
Most teams start with simple roles. Admin, Editor, Viewer. It works fine when you have one product, one customer type, and a handful of users. Then the product grows. You add multi-tenancy. Customers start asking for custom permissions. Compliance requirements show up. And suddenly those three roles aren't enough.
That's the moment most engineering teams start hearing about fine grained access control. But the gap between understanding the concept and actually implementing it well is where most projects stall.
What fine grained access control actually means
Fine grained access control is the ability to make authorization decisions based on multiple factors, not just a user's role. Instead of asking "is this person an admin?" you ask "is this specific person allowed to perform this specific action on this specific resource, given the current context?"
The difference matters more than it sounds.
With coarse grained access control, you assign users to broad roles and those roles grant blanket permissions. An admin can do everything. An editor can edit everything. A viewer can view everything. The granularity stops at the role level.
With fine grained access control, you can express rules like "editors can only edit documents they created" or "managers can approve expenses under a certain threshold but only for their own department" or "support agents can view customer records but only during an active support ticket."
The "fine" in fine grained refers to the level of detail in your authorization logic. Instead of one attribute (role) determining access, you evaluate a combination of who is making the request, what they want to do, what resource they want to do it to, and what conditions apply right now. If you want a broader primer on how authorization works, that's worth reading alongside this.
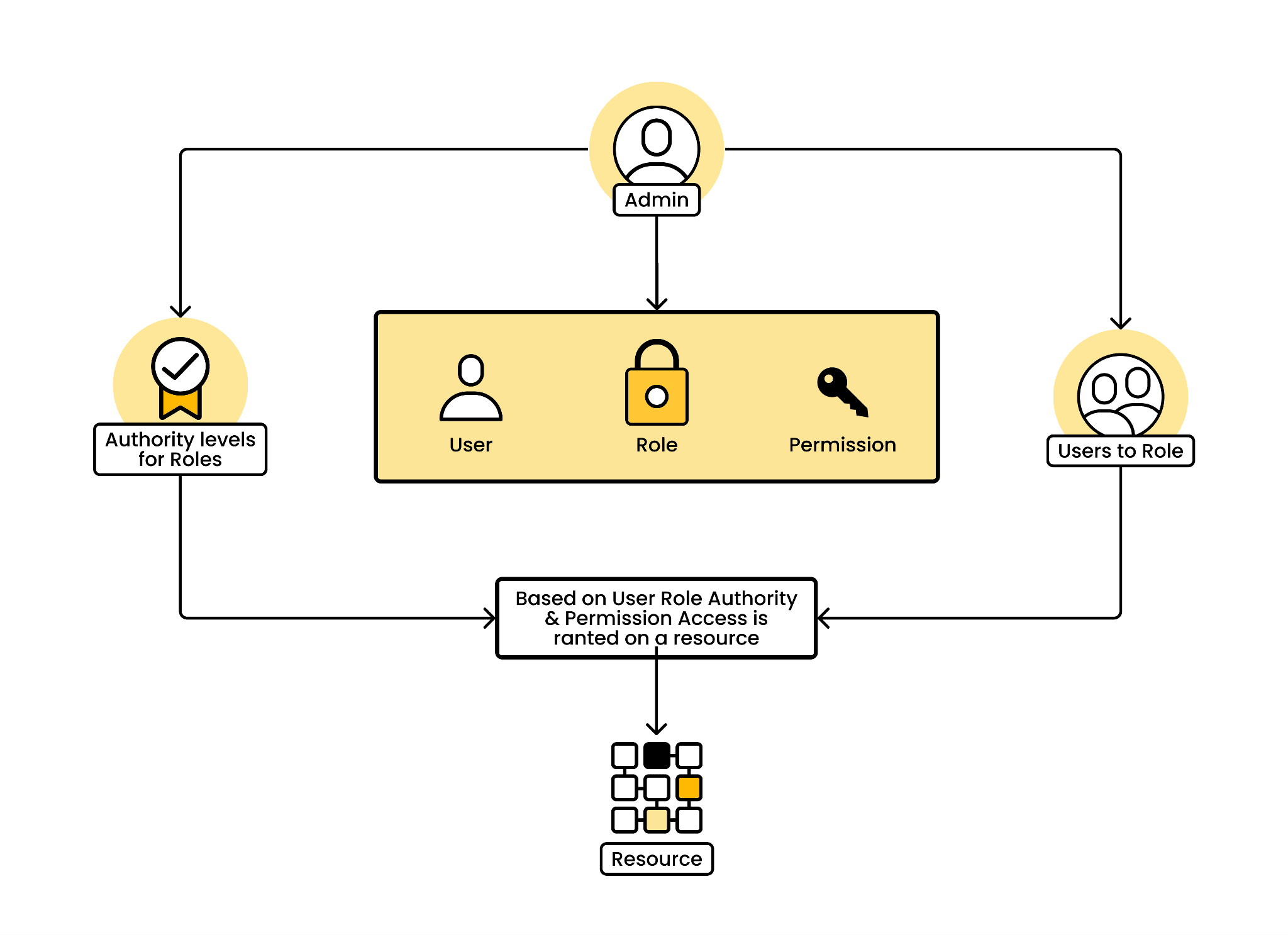
Why coarse grained access control breaks down
The problems usually start showing up in predictable ways.
Role explosion is the most common one. A B2B SaaS platform onboards a new enterprise customer who needs a role that can manage billing but not access user data. Your existing roles don't fit, so you create a new one. Then another customer needs a variation on that. Before long you have more roles than users, and nobody can keep track of what each role actually permits. This is a well-known limitation of role-based access control when it's the only model you're using.
Tenant isolation is the next problem. In a multi-tenant system, Alice might be an admin at Company A but only a viewer at Company B. Coarse grained roles don't carry tenant context, so you end up creating tenant-specific roles like "CompanyA_Admin" and "CompanyB_Viewer." That approach scales exactly as badly as it sounds. The authorization challenges in multi-tenant systems are worth understanding early, because retrofitting tenant-aware permissions later is painful.
Compliance requirements force the issue for many teams. Regulations like SOC 2, HIPAA, and GDPR don't just ask "does the user have access?" They ask "why does the user have access, what's the minimum access needed, and can you prove it?" Answering those questions with a flat role table is difficult. Answering them with attribute-based policies is much more straightforward. Having structured audit logs for every authorization decision makes the compliance conversation significantly easier.
Feature gating and entitlements add another layer. When different pricing tiers unlock different capabilities, you need to combine subscription-level checks with user-level permissions. A free-tier user shouldn't see the same controls as an enterprise customer, even if they share the same role within their organization.
These aren't edge cases. They're the normal trajectory of a B2B product that's growing.
The building blocks of fine grained access control
Every fine grained authorization decision comes down to evaluating a combination of inputs.
The principal is who is making the request. This includes their identity, their roles, their attributes (department, location, clearance level), and their relationships to other entities in the system.
The action is what they want to do. Read, write, delete, approve, transfer, export. The more specific you are about actions, the more control you have.
The resource is what they want to do it to. A document, an account, a database record, an API endpoint. Resources carry their own attributes too. A document might have an owner, a classification level, a creation date, and a tenant.
The context is everything else that matters right now. The time of day, the IP address, whether a support ticket is active, the user's current session risk score. This is what makes authorization dynamic rather than static.
The authorization check brings all of these together. In pseudocode, every fine grained decision looks something like this:
isAllowed(principal, action, resource, context) → allow / deny
The power of fine grained access control comes from being able to write policies that reference any combination of these inputs. "Allow if the user's role is manager AND the resource's department matches the user's department AND the request amount is under the user's approval limit" is a single policy that coarse grained roles simply cannot express.
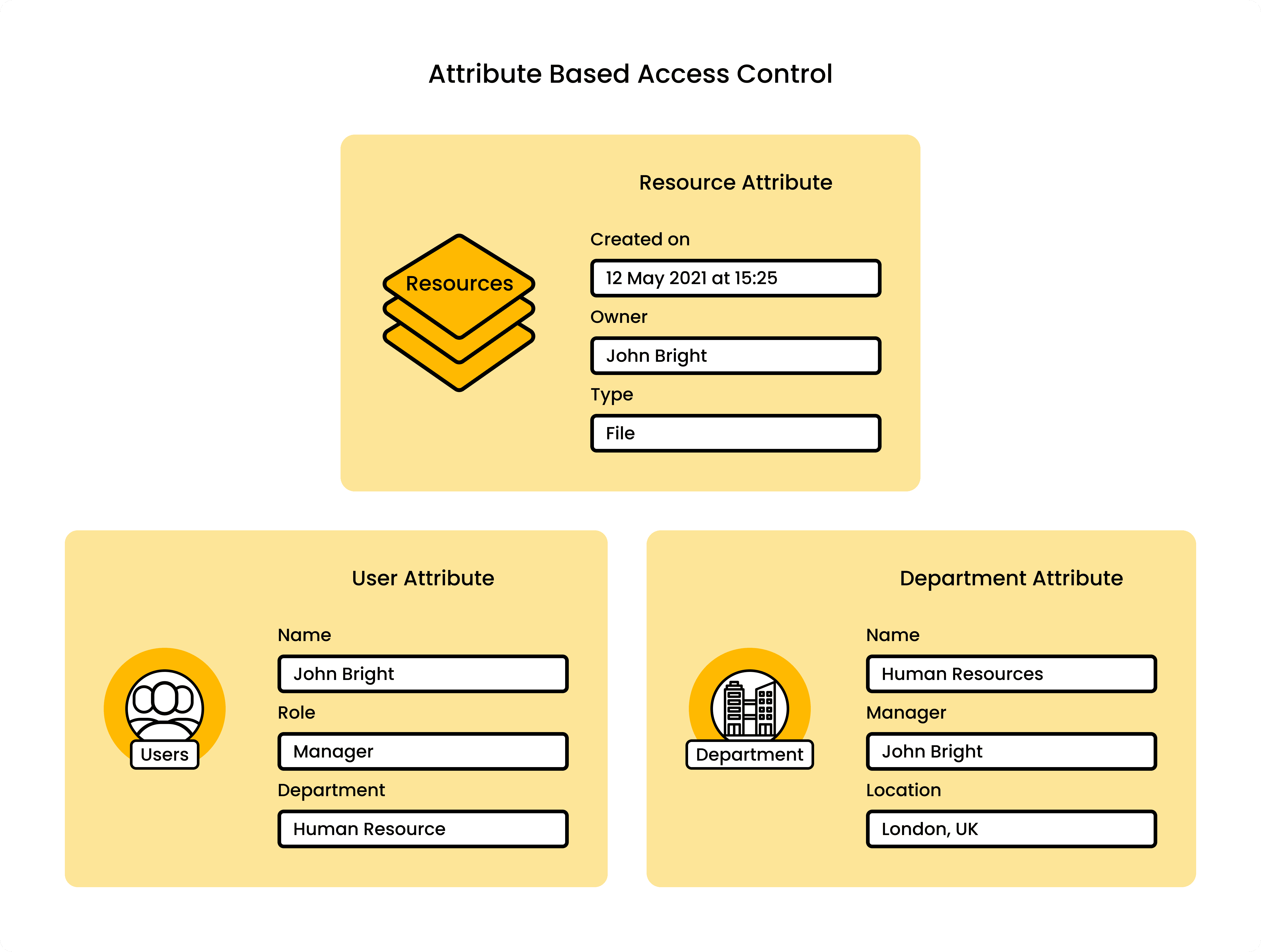
Authorization models that enable fine grained control
There's no single "fine grained access control model." Instead, several models contribute different capabilities, and most real implementations combine them.
RBAC (Role-Based Access Control) is the starting point for most teams. Users are assigned roles, and roles carry permissions. RBAC works well for broad access patterns but starts breaking down when you need exceptions, conditions, or resource-level rules. It's the coarse grained baseline that fine grained systems build on top of. Understanding when RBAC falls short is usually what pushes teams toward more granular models.
ABAC (Attribute-Based Access Control) evaluates policies against attributes of the user, the resource, and the environment. Instead of creating a "ManagerWhoApprovesUnder10k" role, you write a policy that checks the user's role, the resource's value, and the user's approval limit as separate attributes. ABAC is where most teams first start getting real fine grained control. For a deeper look at how ABAC plays out in enterprise service-oriented architectures, that's worth reading.
ReBAC (Relationship-Based Access Control) models permissions based on relationships between entities. "Can this user edit this document?" depends on whether they're the document's owner, a member of the document's team, or have been explicitly shared the document. Google Zanzibar popularized this model, and it's particularly useful for collaborative applications where permission flows through a graph of relationships. If you're evaluating ReBAC, it's worth understanding the trade-offs between PBAC and Zanzibar-style approaches.
PBAC (Policy-Based Access Control) takes these models further by expressing authorization rules as human-readable policies that combine roles, attributes, and relationships in a single evaluation. This is where the real flexibility lives. A PBAC system lets you define rules that check roles, resource ownership, department membership, and time-based constraints all in the same policy without forcing you to pick a single model.
In practice, the lines between these models blur. A well-designed fine grained access control system lets you combine roles, attributes, and relationships in the same policy. Designing an authorization model that accounts for this from the start saves a lot of rework later.
Embedded vs. externalized authorization
One of the first architectural decisions teams face is where the authorization logic lives.
Embedded authorization means the rules are written directly in application code. If-else blocks, middleware checks, decorators on API routes. It's the fastest way to get started and it works well for simple cases. But it tends to look like this:
if (
user.email.includes("@mycompany.com") ||
(
user.company.package === "premium" &&
user.groups.includes("managers")
)
) {
if (user.region === resource.region) {
AuditLog.record("ALLOWED", "edit", user, resource);
} else {
AuditLog.record("DENIED", "edit", user, resource);
}
} else {
AuditLog.record("DENIED", "edit", user, resource);
}
Authorization logic ends up scattered across services, written in different languages, by different teams, at different times. Testing it means testing the entire application. Auditing it means reading source code. Changing a policy means deploying new code. The technical complexities of externalized authorization are real, but they're front-loaded. The cost of keeping authorization embedded only grows over time.
Externalized authorization moves the decision logic out of application code and into a dedicated service. Your application code makes a request and gets back an allow or deny decision. The policies that determine that decision are managed separately. The application code simplifies to this:
if (
await cerbos.isAllowed({ principal: user, resource, action: "edit" })
) {
// allowed
}
Policy changes don't require application deployments. Authorization logic is consistent across services regardless of language. Audit trails come from one place. And compliance teams can review and understand policies without needing to read application source code.
The externalized approach uses a pattern called PDP/PEP separation. The Policy Decision Point (PDP) evaluates requests against policies and returns decisions. The Policy Enforcement Point (PEP) sits in your application code and makes the check, then enforces the result.
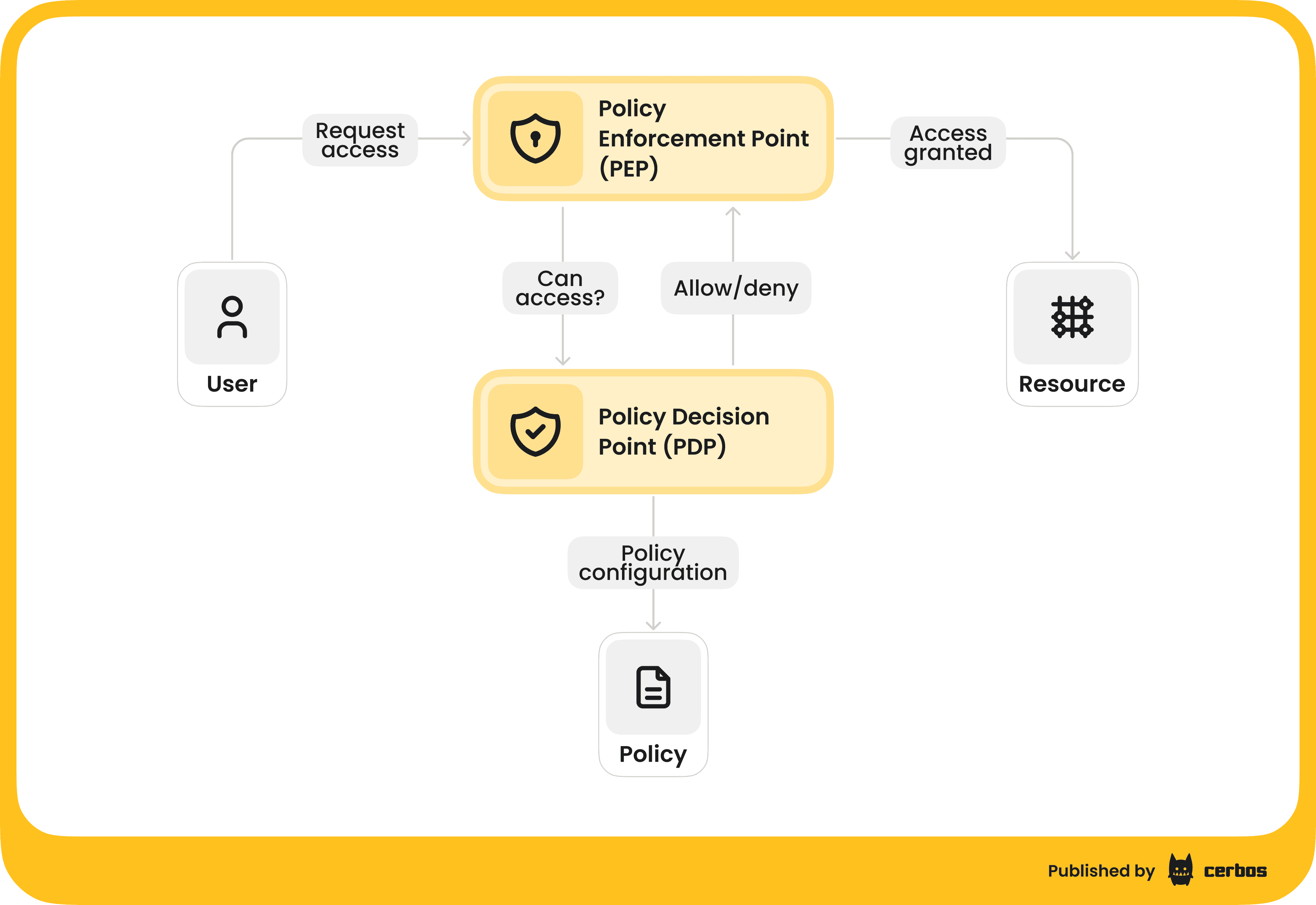
What fine grained access control looks like in practice
Abstract models are useful, but what does this look like as actual policy?
Here's a basic example. You have a blogging platform where users can create, update, and delete posts. Admins can do anything, but regular users should only be able to modify their own content. That's a resource-level ownership check, and in a policy-based system it looks like this:
apiVersion: api.cerbos.dev/v1
resourcePolicy:
version: default
resource: post
rules:
- name: allow_all_actions
actions: ["*"]
effect: EFFECT_ALLOW
roles:
- admin
- name: allow_user_to_update_and_delete_posts
actions: ["update", "delete"]
effect: EFFECT_ALLOW
roles:
- user
condition:
match:
expr: request.resource.attr.user_id == request.principal.id
That's RBAC and ABAC working together in one policy. The admin role gets blanket access. The user role gets access only when the resource's owner ID matches their own.
Now take a more complex scenario. An HR system where access depends on department membership, office location, device trust, risk scores, and business hours:
apiVersion: api.cerbos.dev/v1
resourcePolicy:
version: "default"
resource: "employee_record"
rules:
- actions: ["read", "update"]
effect: "EFFECT_ALLOW"
roles: ["employee"]
condition:
match:
expr: request.resource.attr.department == request.principal.attr.department
- actions: ["read", "approve"]
effect: "EFFECT_ALLOW"
roles: ["finance_manager"]
condition:
match:
expr: request.principal.attr.location in ["HQ", "Regional Office"]
- actions: ["read"]
effect: "EFFECT_ALLOW"
roles: ["hr_manager"]
condition:
match:
expr: request.principal.attr.device_trusted == true
- actions: ["read", "update"]
effect: "EFFECT_ALLOW"
roles: ["security_officer"]
condition:
match:
expr: request.principal.attr.risk_score < 50
- actions: ["read", "approve"]
effect: "EFFECT_ALLOW"
roles: ["line_manager"]
condition:
match:
expr: now().getHour >= 9 && now().getHour() <= 17
Each rule evaluates a different combination of attributes. Department matching, location restrictions, device trust, risk scoring, time-based access. That's fine grained access control in practice. Five different conditions, all expressed declaratively, all evaluated in a single resource policy without touching application code.
You can also define derived roles to handle ownership patterns that come up repeatedly:
apiVersion: api.cerbos.dev/v1
derivedRoles:
name: example_derived_roles
definitions:
- name: OWNER
parentRoles: [USER]
condition:
match:
expr: R.attr.owner == P.id
- name: MANAGERS
parentRoles: [IT_ADMIN, JR_MANAGER, SR_MANAGER, CFO]
Instead of checking ownership in every policy rule, you define the OWNER derived role once and reference it across policies. When a user's ID matches the resource's owner attribute, they automatically get the OWNER role for that specific request.
Getting fine grained access control right
Teams that have implemented fine grained access control successfully tend to follow a few patterns.
Start with your actual access patterns, not a theoretical model. Before picking RBAC vs. ABAC vs. ReBAC, map out what your users actually need to do and what conditions apply. Most real systems need a combination, and starting from real requirements prevents you from over-engineering.
Externalize early. The longer authorization logic stays embedded in application code, the harder it is to extract later. Even if your rules are simple today, separating authorization logic from your application from the start gives you room to grow without a migration.
Think about authorization data. Fine grained decisions require rich context. Your PDP needs to know the user's attributes, the resource's attributes, and any relevant relationships. Where does that data come from? How fresh does it need to be? Teams that plan their data flow early avoid the "we have the policy but not the data to evaluate it" problem later.
Test policies like code. Authorization policies are logic. They have edge cases, they interact with each other, they can regress. Treat them with the same rigor as application code. Write test cases, run them in CI, catch breaking changes before they hit production.
Build for auditability from the start. Every authorization decision should be logged with enough context to answer "who accessed what, when, and why was it allowed?" later. This is a compliance requirement for most regulated industries, but it's also invaluable for debugging permission issues. A well-structured audit log entry looks like this:
{
"timestamp": "2023-01-05T15:51:13Z",
"requestId": "01GP1A25FW6BVX9JWYM9M6T0Z0",
"principal": {"id": "sally", "roles": ["employee"], "attr": {"department": "SALES"}},
"resource": {"kind": "employee_record", "id": "record123", "attr": {"department": "SALES"}},
"action": "read",
"effect": "EFFECT_ALLOW",
"policy": "resource.employee_record.vdefault"
}
Every decision is traceable back to the specific principal, resource, action, and policy that produced it.
Fine grained access control for non-human identities
One area that's increasingly important is applying fine grained access control to non-human identities. API keys, service accounts, and AI agents all make requests on behalf of users or systems, and they need the same level of authorization scrutiny.
AI agents are a particularly interesting case. When an agent acts on behalf of a user, the question isn't just "what can this agent do?" It's "what can this agent do on behalf of this specific user in this specific context?" That requires evaluating both the agent's identity and the delegating user's permissions together.
The same policy patterns that work for human users apply to agents and services. Here's how a policy for securing an MCP server with fine grained tool-level access looks:
apiVersion: "api.cerbos.dev/v1"
resourcePolicy:
version: "default"
resource: "mcp::expenses"
rules:
- actions: ["list_expenses"]
effect: EFFECT_ALLOW
roles: ["admin", "manager", "user"]
- actions: ["add_expense"]
effect: EFFECT_ALLOW
roles: ["user"]
- actions: ["approve_expense", "reject_expense"]
effect: EFFECT_ALLOW
roles: ["admin", "manager"]
- actions: ["delete_expense", "superpower_tool"]
effect: EFFECT_ALLOW
roles: ["admin"]
Each tool the agent can call is treated as an action on a resource. The policy determines which roles can invoke which tools. You can add conditions on top of that, for example restricting approval actions to amounts below a threshold:
- actions: ["approve_expense"]
effect: EFFECT_ALLOW
roles: ["manager"]
condition:
match:
expr: request.resource.attr.amount < 1000
Service-to-service communication has the same challenge at a different scale. In a microservices architecture, services make requests to each other constantly. Without fine grained controls, a compromised service has the same access as every service it can reach. Applying the principle of least privilege to service identities means treating every service-to-service call as an authorization decision.
Conclusion
The gap between "we have roles" and "we have fine grained access control" isn't as wide as it looks. It starts with moving authorization logic out of your application code and into policies that can be managed, tested, and audited independently. From there, you layer in the attributes, relationships, and context that your product actually needs. You don't have to solve every edge case on day one. But you do need an architecture that won't force a rewrite when those edge cases inevitably show up.
You can start experimenting with fine grained policies today in Cerbos Hub, which includes a free tier for testing and development. For a deeper walkthrough of the architecture, our ebook “Building a scalable authorization system” covers the step-by-step blueprint from design to deployment.
FAQ
Tagged in





