
If your organization runs AI agents in production, there is a good chance their traffic already funnels through an AI gateway. LiteLLM is one of the most widely deployed, a single proxy that gives every user and every agent one endpoint for hundreds of models and, increasingly, for MCP tool servers too.
That concentration is convenient, and it is also the problem. The gateway authenticates callers, routes requests, tracks spend. What it does not answer is the question that matters most for AI agent security. Should this specific principal be allowed to do this specific thing, right now, with these specific inputs?
We built an integration that answers it with Cerbos, and recorded a demo you can watch below.
One proxy, three authorization questions
Every request that crosses an AI gateway raises the same three questions.
Which models can this user or agent call? Your support agents probably should not be running the most expensive frontier model, and your interns probably should not be running anything trained for code execution.
Which tools should the model ever see? If an agent declares a refund tool in its request, the model will happily call it. The safest deny is the one where the model never knew the tool existed.
And what is the caller actually allowed to do with a tool? This is the question role checks cannot answer. An admin may be allowed to issue refunds in general, and still must not be able to refund $2,000 against a ticket that is not theirs.
Most gateways stop at the first question, enforced through static config or API key scopes. The second and third need externalized authorization, decisions made against policy at request time, with the full context of who is asking and what they are asking for.
How the integration works
LiteLLM exposes official extension points for exactly this kind of delegation, and the integration plugs into them with two short Python files. No forked proxy, no sidecar rewriting traffic.
A custom auth function maps the caller's JWT to a principal. A guardrail then intercepts every chat completion and every MCP tool invocation before it leaves the proxy, and asks Cerbos for a decision. Model denied, the request stops with a 403. Tool denied, it is silently stripped from the request so the model never sees it. MCP call denied, the invocation never reaches the tool server.
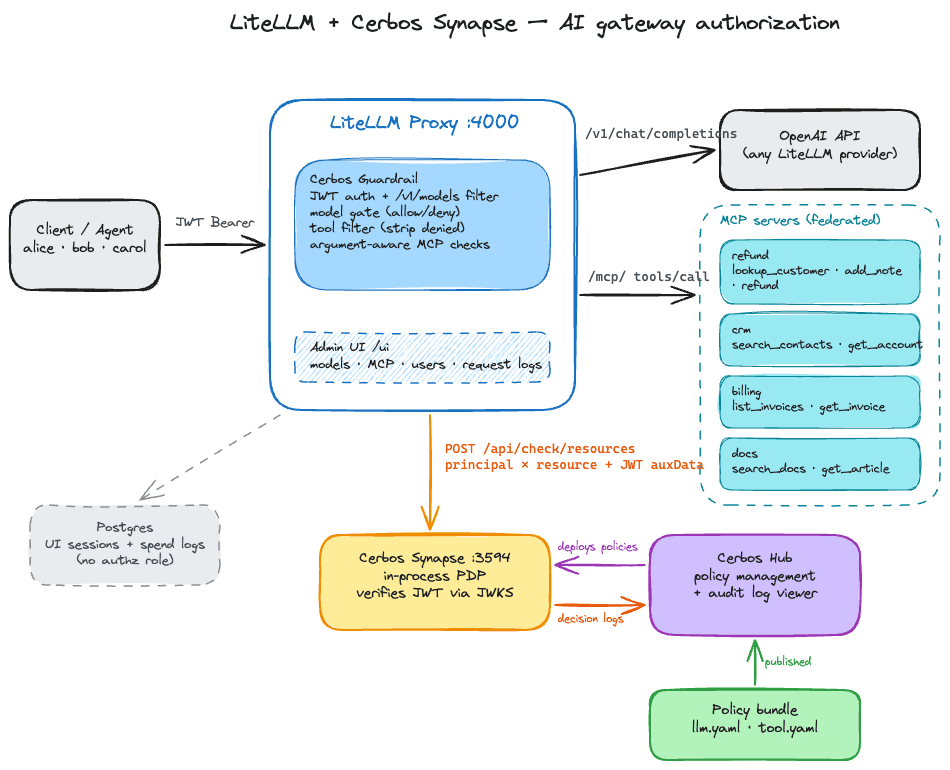
The rules themselves live in policy, not in proxy config. Changing who can use which model, or tightening a tool's conditions, is a policy deployment. The gateway and the applications behind it never change.
Decisions that read the arguments
The part worth slowing down for is the third question. When an agent invokes an MCP tool through the gateway, Cerbos receives the tool name and the actual invocation arguments, and evaluates them against attributes of the caller.
- name: refund-binding
actions: [tools/call/refund]
effect: EFFECT_DENY
roles: ["*"]
condition:
match:
any:
of:
- expr: R.attr.arguments.ticket_id != P.attr.assigned_ticket
- expr: R.attr.arguments.amount_cents > P.attr.refund_limit_cents
Ten lines of YAML, and the refund tool is now bound to the caller's assigned ticket and their personal refund cap. The join between principal and invocation lives in policy where it can be reviewed, tested, and versioned, not buried in gateway middleware. This is the same model we describe in our guide to MCP authorization, applied at the gateway hop.
Evidence on both sides
Authorization without evidence is half a feature. The integration produces an audit trail in both planes.
In the LiteLLM admin UI, every denial shows up in the request logs attributed to the principal, with the reason in plain text. When the guardrail strips a tool, the guardrail record shows exactly which tools were allowed and which were dropped.
On the Cerbos side, the decision log records every check. The principal and their attributes, the derived roles they matched, the policy that answered, and for tool calls the arguments that were judged. The $2,000 refund attempt sits in the log right next to the $1,000 cap that denied it. With Cerbos Hub, those decision logs stream to a central audit viewer alongside every other service Cerbos protects.
Bring your own gateway
LiteLLM is one example, not a requirement. Cerbos is deliberately agnostic about where enforcement happens. That is the point of decoupling policy from enforcement. Gateways will keep evolving, agents will arrive over protocols that do not exist yet, and the authorization layer should not care. One vocabulary for decisions, one place to audit them, whichever proxy happens to sit in the traffic path.
Getting started
If agents are already moving through a gateway in your stack, this is a practical first enforcement point. Start with model access, add tool exposure, then tighten down to argument-level rules as your policies mature.
Try Cerbos Hub to manage and deploy the policy bundle from this demo, or book a call to talk through securing your agent stack.
Go deeper:
- Zero Trust for AI: Securing MCP servers (eBook) for a playbook on locking down the tool layer agents depend on
- Securing AI agents and non-human identities in enterprises (eBook) for the wider NHI governance picture
FAQ
Tagged in





