Externalized authorization is the goal. Pull the access control logic out of your applications, centralize it in a policy engine, and make every decision auditable. For new builds, this works well. You add the Cerbos SDK, call the PDP on every request, and ship. The authorization model is clean from day 1.
But new builds aren't the whole picture. They're not even most of the picture.
The reality of enterprise software is that your estate is a mix. A few modern services with proper SDK integrations. A vendor portal you bought in 2019 that you can't modify. A payroll system from 2008 running on a VM. An internal tool someone built in PHP that "just works." Maybe a mainframe behind a terminal emulator. These systems have users, they have sensitive data, and they have authorization logic that ranges from rudimentary to nonexistent.
If your externalized authorization strategy only covers the new builds, you've got fragmentation. Half your systems are governed by central policy. The other half are governed by whatever the original developer decided 15 years ago (or nothing at all). Your audit trail has gaps. Your compliance story has caveats. Your security posture has blind spots that map exactly to the systems that are hardest to change.
The question isn't whether to externalize authorization. It's how to bring the systems you can't rewrite along for the ride.
The gateway pattern
You can't add an SDK to an application you can't modify. But you can put a reverse proxy in front of it.
Cerbos Synapse and Envoy make this concrete. Envoy sits in front of the legacy application as a reverse proxy. It handles modern authentication (OAuth2/OIDC against your identity provider). On every request, it calls Synapse for an authorization decision. Synapse evaluates a Cerbos policy and tells Envoy whether to allow or deny. If allowed, the request is proxied to the application with identity headers attached. If denied, a 403 is returned and the request never reaches the app.
Browser
│
▼
┌──────────────────────────────────┐
│ Envoy │
│ │
│ 1. OAuth2/OIDC authentication │
│ (Keycloak, Entra ID, Okta) │
│ │
│ 2. ext_authz → Synapse │
│ (authorization check) │
│ │
│ 3. Proxy to application │
│ (with identity headers) │
└──────────────────────────────────┘
│ │
▼ ▼
┌──────────┐ ┌──────────────┐
│ Synapse │ │ Legacy App │
│ │ │ │
│ Cerbos │ │ No changes │
│ PDP │ │ No SDK │
│ (in-proc)│ │ No awareness │
│ │ │ of Cerbos │
│ Hub │ │ │
│ (audit) │ │ │
└──────────┘ └──────────────┘
The application doesn't change. It doesn't need a Cerbos SDK. It doesn't need to know about Cerbos at all. It just serves requests that arrive through Envoy, and those requests only arrive if the policy said they could.
The same Cerbos policy language. The same Hub instance. The same audit trail. The legacy system joins the same externalized authorization framework as your modern services, just through a different integration point.
What the policies look like
The policy maps routes to roles. Resource kind is the application identifier. Actions are HTTP methods. Conditions match on the request path.
apiVersion: api.cerbos.dev/v1
resourcePolicy:
version: "default"
resource: "legacy-payroll::route"
rules:
- actions: ["GET"]
effect: EFFECT_ALLOW
roles: [USER, MANAGER, ADMIN]
condition:
match:
any:
of:
- expr: R.attr.path == "/" || R.attr.path == ""
- expr: R.attr.path.startsWith("/paystubs")
output:
when:
ruleActivated: |-
{"x-cerbos-principal-id": P.id, "x-cerbos-roles": P.roles}
- actions: ["GET"]
effect: EFFECT_ALLOW
roles: [MANAGER, ADMIN]
condition:
match:
any:
of:
- expr: R.attr.path.startsWith("/employees")
- expr: R.attr.path.startsWith("/payroll")
output:
when:
ruleActivated: |-
{"x-cerbos-principal-id": P.id, "x-cerbos-roles": P.roles}
- actions: ["GET"]
effect: EFFECT_ALLOW
roles: [ADMIN]
condition:
match:
any:
of:
- expr: R.attr.path.startsWith("/reports")
- expr: R.attr.path.startsWith("/admin")
output:
when:
ruleActivated: |-
{"x-cerbos-principal-id": P.id, "x-cerbos-roles": P.roles}
That's the entire authorization model for a payroll system. Read it top to bottom:
- Everyone can see the dashboard and their own paystubs
- Managers and admins can see employee records and payroll runs
- Only admins can see reports and admin config
When a regular user tries to hit /employees, they get a 403 before the application even knows someone tried. When a manager hits the same URL, the request goes through with their identity attached.
The output block on each rule injects the principal's identity and roles as response headers. The application can read these if it wants to (for display, for further filtering), but it doesn't have to. The authorization decision already happened at the gateway.
Coarse-grained, but consistent
Gateway-level authorization is coarse-grained. You're matching on URL paths and HTTP methods, not on individual database records. That's a real limitation.
But coarse-grained control applied consistently across every system is better than fine-grained control applied to the 3 modern services while 15 legacy systems have no external governance at all.
And it's not just coarse. You can get to medium-grained pretty quickly:
/employeesvs/employees/:idcan have different rulesGETvsPOSTvsDELETEon the same path can have different rules- Query parameters and headers are available in
R.attrfor conditional logic - Principal attributes from the JWT (department, clearance, location) can drive conditions
You're not going to get row-level filtering through a gateway. But you can get "only managers can see employee records" and "only admins can run reports" and "only the finance team can access payroll data." For a system that previously had no external authorization, that closes a significant governance gap.
Pulling in more context: device posture, risk signals, location
The JWT only tells you so much. Username, roles, maybe a few claims your IdP decided to include. That's enough for basic role-based decisions, but real authorization in 2026 needs more than "what role does this user have."
Synapse can fetch additional context at decision time through its data source extensions. Before the policy evaluates, Synapse calls out to whatever systems hold the signals you care about, attaches the results to the principal, and makes them available in policy expressions. The legacy app still doesn't know any of this is happening.
Device posture is the one I think matters most for legacy systems. Your MDM or endpoint protection platform (Crowdstrike, Jamf, Intune, Kandji, SentinelOne) knows things about the user's device that nobody else does:
- Is this a managed device, or a personal one?
- Is disk encryption enabled?
- Is the OS up to date?
- Is endpoint detection running and reporting healthy?
- When was the last successful security scan?
- Is the device in a known-compromised state?
Plug a data source extension into your MDM's API, and that data flows into the policy:
- actions: ["GET"]
effect: EFFECT_DENY
roles: [MANAGER, ADMIN]
condition:
match:
any:
of:
- expr: P.attr.device.managed != true
- expr: P.attr.device.disk_encrypted != true
- expr: P.attr.device.os_up_to_date != true
output:
when:
ruleActivated: |-
{"x-cerbos-deny-reason": "device-posture-failed"}
Now access to the payroll system is conditional on the device being in a healthy, managed state. An admin trying to view reports from an unmanaged personal laptop gets blocked. The same admin on their managed work device gets through. The legacy app never learns any of this; it just receives requests that have already passed the device check.
Device posture isn't the only thing you can pull in. The same pattern works for any external signal:
| Signal source | What you get | Example policy use |
|---|---|---|
| MDM / EDR | Device managed state, encryption, OS version, threat status | Block access from unmanaged or non-compliant devices |
| IdP risk scoring | Login risk score, anomaly detection, impossible travel | Deny high-risk sessions, even for valid users |
| Geolocation (IP-based or device-reported) | Country, region, network type | Restrict sensitive routes to corporate network or approved countries |
| HR system | Employment status, current manager, department, start date | Auto-revoke access for terminated employees before IdP catches up |
| Time-of-day / on-call schedules | Whether the user is currently on shift | Restrict admin actions to business hours or on-call windows |
| Ticketing system | Open change tickets, approved access requests | Allow elevated access only when there's an approved ticket |
Each one is a data source extension that Synapse calls when it needs the data. Results are cached (in-memory or Redis, with configurable TTLs), so you're not hammering external APIs on every request. The policy expresses the rule. Synapse fetches what it needs to evaluate it.
This is what makes the gateway pattern more than just "RBAC at the proxy." You're not just checking who the user is. You're checking the full context of the request: who, what device, from where, at what time, with what risk signals attached. All of that runtime context becomes available to a policy that the legacy app doesn't even know exists.
For systems that hold sensitive data (and most legacy systems do), this is the kind of context-aware enforcement that compliance frameworks increasingly expect. Zero trust principles, conditional access, continuous evaluation. The legacy app can't do any of this on its own. Synapse brings it to them.
Authentication: the double login reality
A lot of these legacy systems have their own login forms with their own user databases. Some hardcoded credentials. Maybe an LDAP integration that nobody wants to touch.
Envoy's OAuth2 filter adds a modern authentication layer on top: SSO through your identity provider, OIDC tokens, proper session management. If the legacy app supports SSO or can be configured to trust the identity provider, the experience is seamless. One login, and the user is authenticated at both the gateway and the application.
If it doesn't (and many genuinely old systems don't), the user logs in twice: once at the IdP via Envoy, once at the legacy app's own login form. That's not ideal, but it's the reality of working with systems you can't modify. The gateway login establishes who the user is for authorization purposes. The legacy login gets them into the app. Both are necessary, and trying to eliminate the double login usually means modifying the application, which is exactly what you're trying to avoid.
The important thing is that the authorization decision happens at the gateway, using the IdP identity. Synapse extracts roles from the JWT, so your IdP becomes the source of truth for who can access what. Change someone's role in Keycloak (or Entra ID, or Okta), and their access changes on the next request. The legacy app's internal user management continues to work as it always has; it just can't override the gateway's decision about whether the request should have arrived in the first place.
Visibility before control
Before Synapse, you probably have no idea who's accessing what in that legacy system. Maybe there are access logs in a file somewhere on the VM. Maybe not.
With Synapse connected to Hub, every request is an audited authorization decision. You can see who accessed which routes, when, with what roles, with what device posture, and whether they were allowed or denied.
This alone is worth the setup. Before you write a single deny rule, you're getting a complete picture of how the application is actually used. Run it in observe mode for a week. Look at the access patterns. Then write policies based on what you actually see.
For compliance, this is the part that matters most. The legacy systems that are hardest to govern are usually the ones that hold the most sensitive data. Payroll. HR records. Financial reporting. Getting audit coverage over these systems, even at the route level, closes gaps that are otherwise invisible.
The modernization path
Gateway authorization isn't the end state. It's the first step in a path that doesn't require a rewrite.
Phase 1: Observe. Deploy Synapse in front of the application with no deny rules. Everything passes through. You get a full audit trail of who accesses what. This takes an afternoon to set up and immediately answers questions that were previously unanswerable.
Phase 2: Coarse control. Write route-level policies based on what you observed. Block the obvious stuff: non-admin users hitting admin routes, external users hitting internal endpoints. Test the policies in Hub before deploying.
Phase 3: Context-aware control. Pull in additional signals via data source extensions. Device posture, risk scores, location, time-of-day, HR status. The same policies now make decisions based on the full context of the request, not just the user's role.
Phase 4: Application awareness. If and when the application gets modified (even lightly), it can start reading the x-cerbos-principal-id and x-cerbos-roles headers that Synapse injects. Use these for in-app display, for filtering data, or for additional checks. The app doesn't need a Cerbos SDK for this. It's just reading HTTP headers.
Phase 5: Full integration. If the application ever gets rewritten, it can call the Cerbos PDP directly for fine-grained, record-level authorization. The policies in Hub already exist. The audit trail is already flowing. The roles, attributes, and external context signals are already defined. You're extending an existing authorization model, not building one from scratch.
Each phase is independently valuable. Most organizations will get meaningful value from phases 1, 2, and 3 alone.
One authorization framework, no fragmentation
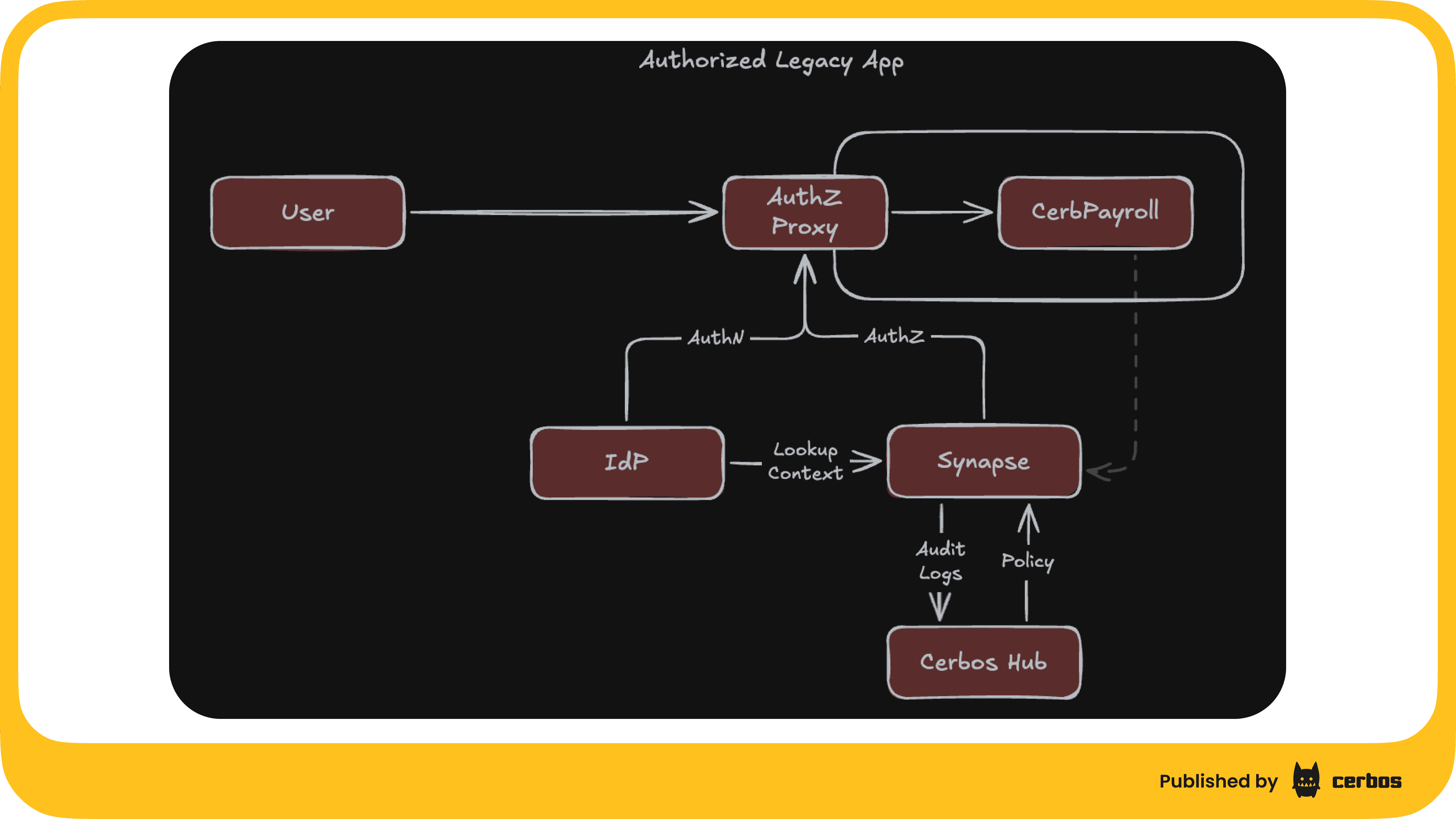
The real payoff shows up when you zoom out.
Your modern services call the Cerbos PDP directly via the SDK. Your infrastructure systems (Trino, Kafka, Envoy) go through Synapse's protocol translation. Your legacy systems go through Synapse and Envoy at the gateway.
3 different integration patterns, but they all feed into the same policy framework:
- Same policy language across every system
- Same Hub instance for management, testing, and distribution
- Same audit trail for compliance reporting
- Same role definitions from the same identity provider
- Same external context signals (device posture, risk, location) available to every policy
When the auditor asks "who has access to what, from where, on what device," you have one place to look. When you need to revoke someone's access, you change it in one place and it takes effect everywhere: the modern services, the infrastructure, and the legacy systems. When you tighten device posture requirements, the same rule applies across the entire estate.
That's the point. Externalized authorization only works as a strategy if it covers the whole estate. The systems you can't rewrite are the ones that need governance the most. Synapse and Envoy bring them into the same framework without requiring a single line of code to change.
Next steps
If you're building an externalized authorization strategy and need to bring legacy systems along, we'd like to show you how Synapse fits into your stack. Reach out to the Cerbos team to get started. Or explore Cerbos on your own.
FAQ
Tagged in





