Earlier this year, Cerbos co-founder and Chief Product Officer Alex Olivier took the stage at DevDays Europe alongside experts Kenneth Rohde Christiansen, Paul Dragoonis, Romano Roth, and Victor Lyuboslavsky. Their panel discussion “Building the Future: Trends in Modern Application Architecture” tackled everything from AI’s impact on cloud infrastructure to the perennial microservices vs. monolith debate.
You don’t need to have heard the panel to follow along, but if you’re curious, you can check out the recording above. Let’s dive in.
AI’s impact on infrastructure. From cloud to on-prem
It’s impossible to discuss modern architecture today without addressing the AI revolution. Alex Olivier noted that many teams are now re-architecting systems to accommodate AI workloads, especially the heavy compute demands of training and running large models. One current pain point is access to GPUs and other AI accelerators in the cloud. Demand is so high that cloud GPU capacity is scarce and coveted.
This scarcity is pushing companies to get creative. Alex explained that DevOps and product teams are collaborating to “move the compute to where the GPUs are available.” In practice, this often means adopting a multi-cloud or hybrid cloud strategy. A company that once deployed everything to AWS might now also burst into Google Cloud to leverage specialized TPUs for an ML model. Suddenly, teams must provision resources across cloud providers and even on-premises environments, and ensure those components can securely talk to each other. Frameworks like SPIFFE/SPIRE can help by providing a cloud-agnostic way to assign cryptographic identities to workloads across environments. In other words, organizations are seeking portability and workload identity federation so that an AI service running on Google Cloud can authenticate and integrate with services in their AWS or on-prem setup.
The panel also discussed the rise of on-premises AI and specialized hardware at the edge. With device makers adding NPUs to laptops and phones, some AI tasks can run locally. Kenneth pointed out examples like Microsoft’s Copilot integration on PCs. However, Alex cautioned that the most cutting-edge models will likely remain available only via cloud APIs or hosted services. You might run a smaller open-source model like Llama 3 on your own hardware, but if you need the latest GPT-5 or a multimodal model, you’re probably going to “push your compute” to a cloud provider’s data center.
Victor Lyuboslavsky added that some companies try to mandate local-only AI usage to avoid sharing sensitive data with cloud providers, but developers often chafe at the reduced capabilities. Local models simply aren’t as powerful or convenient as their cloud-hosted counterparts. This tension is driving interest in privacy-preserving AI and hybrid approaches. For example, using local AI for certain tasks while calling out to cloud APIs for others, all within one application.
The on-premise comeback and data sovereignty
The pendulum is swinging back toward on-premises infrastructure in many cases, even beyond AI. Romano Roth observed that in Switzerland and Austria, quite a few companies are moving workloads off the public cloud or exploring local cloud providers. Regulatory and geopolitical concerns are a big factor. Kenneth cited an incident where a U.S. tech giant, under legal pressure, deleted a European user’s data - a wake-up call that relying solely on foreign cloud providers can be risky. Many organizations have grown wary that if things get politically tense, “they can remove my cloud tomorrow, my data, my AI.”
This is fueling interest in data locality and sovereign cloud solutions. As Alex put it, every week, another region introduces data residency laws requiring certain information to stay within its borders.
A sovereign cloud is essentially a cloud environment designed to adhere to a nation’s data residency and compliance mandates, ensuring data stays under local control.
Major cloud vendors have responded with offerings like AWS Outposts and Azure Stack - extensions of their cloud infrastructure that live in your data center, to address latency, sovereignty, or regulatory needs. Romano noted that clients now ask for architectures that allow moving workloads between providers or back on-prem on demand. Modern applications may need the flexibility to deploy anywhere - public cloud, private data center, or edge - depending on cost, compliance, and performance.
Microservices vs. monolith: Finding the right balance
About a decade ago, microservice architecture took the industry by storm, everyone was breaking apart monoliths in the name of agility. But the panel agreed that the pendulum swung too far before settling back to center. Paul Dragoonis quipped that many teams went from having one problem to having five:

Microservices do offer real benefits, but only when applied judiciously. Victor Lyuboslavsky highlighted that their biggest advantage is enabling large engineering organizations to work in parallel. He cited Amazon’s famous “two-pizza team” rule - a small team (feedable by two pizzas) can own a microservice, which allows a big organization to function as many independent squads rather than one monolithic team. Team autonomy and velocity are major draws for microservices, letting multiple teams ship features without stepping on each other’s toes.
At the same time, breaking everything into microservices isn’t a silver bullet for resilience or scale. Paul argued that resilience comes from how you design your system, not simply how many deployable units you have. A monolith can be made highly scalable and fault-tolerant (think horizontally scaling a single app across hundreds of containers) if it’s stateless and well-architected. For example, a database outage can bring down a monolith or a microservices suite just the same, and one well-structured service is often easier to keep reliable than 50 interconnected ones. “If the one database goes down, that’s the real problem,” Paul noted.
The consensus: start simple, and only introduce microservices when you have a clear reason. Alex recommended beginning with a modular monolith approach. That means internally structuring your application into clean, domain-based modules, with well-defined interfaces, but deploying it as a single unit. At least initially. You get many benefits of logical separation without the operational overhead of multiple services. And a modular monolith sets you up for an easier transition to microservices down the road if scaling or team structure demands it. “Keep sensible boundaries from day one so you don’t shoot yourself in the foot later,” Alex advised.
For those who do go the microservices route, the panel emphasized doing it right. That means truly decoupling services. Each service should manage its own data - its own database or schema. And services should communicate in an asynchronous, resilient fashion, say, via an event bus or message queue, rather than making brittle synchronous calls that create tight coupling.
Paul stressed the importance of event-driven architecture and eventual consistency. Instead of Service A calling Service B directly, and crashing if B is down, Service A can publish an event that Service B and others consume. If B is offline, it will process the event once it’s back, allowing the overall system to recover gracefully. Designing for eventual consistency and loose coupling mitigates the risk that one service’s failure cascades into an outage of the entire system.
Romano cautioned against adopting microservices just because they’re trendy without analyzing requirements. The choice between monolith vs. microservices, or any style, depends on context: team size, domain complexity, scalability needs, regulatory constraints, and so on. There’s no one-size-fits-all. Instead of following hype, do the analysis - what problem are you trying to solve? Every approach has trade-offs: splitting into microservices adds complexity, while staying monolithic can introduce its own challenges. The art of architecture is choosing the right trade-offs for your situation.
Avoiding vendor lock-in with open standards and smart design
Another audience question raised the issue of vendor lock-in. How can we avoid getting stuck with a particular cloud or product?
Alex noted that compared to 10–15 years ago, we’re in a better place now thanks to common standards and open source alternatives. Containers, for instance, use the OCI image format, so you’re not tied to one company’s registry. You can run those same images on any Kubernetes cluster, in any cloud or on-prem. Kubernetes has become a de facto standard for orchestration. And for data, technologies like PostgreSQL are nearly ubiquitous, with compatible managed offerings on all major clouds. If your application sticks to standard interfaces such as SQL, HTTP, OAuth2 for identity, etc., it’s much easier to swap out underlying components without massive changes.
“Protocols, not vendors,” as Paul put it. He suggested focusing on widely supported protocols and designing modularly so that your core business logic isn’t entangled with any one vendor’s SDK or quirks. An architectural pattern like hexagonal architecture (ports-and-adapters) is useful here. In a hexagonal design, your business logic lives in the center, and all external interactions (databases, cloud services, third-party APIs) are handled by adapter layers at the edges. If you need to switch from one cloud service to another, you can swap out the adapter without rewriting core code. Victor echoed this advice: ensure no internal module directly calls a cloud-specific library when it could call an abstraction instead.
Of course, some lock-in is inevitable. Romano wryly observed, “I can guarantee you will die one death when it comes to vendor lock-in.” Every choice, even adopting open source tech, introduces some constraints. You might avoid cloud platform lock-in by using Kubernetes, but then you’re “locked in” to the Kubernetes ecosystem. The key is to be aware of what you’re committing to and make that trade-off consciously. Choose mature technologies that have multiple vendors or implementations so you keep options open. And if you adopt a proprietary service for a compelling reason, say, a unique AI API, encapsulate its usage so you could replace it later if needed.
Alex emphasized the role of open standards in preserving flexibility. He mentioned the OpenID Foundation’s new authorization working group - AuthZEN, which Cerbos is a key member of. The working group aims to define a common authorization API to reduce vendor lock-in risk. But such standards will only succeed if customers demand them - “you need to challenge your vendors to use open standards,” Alex said. In other words, if architects insist on interoperable solutions, vendors will feel pressure to prioritize them.
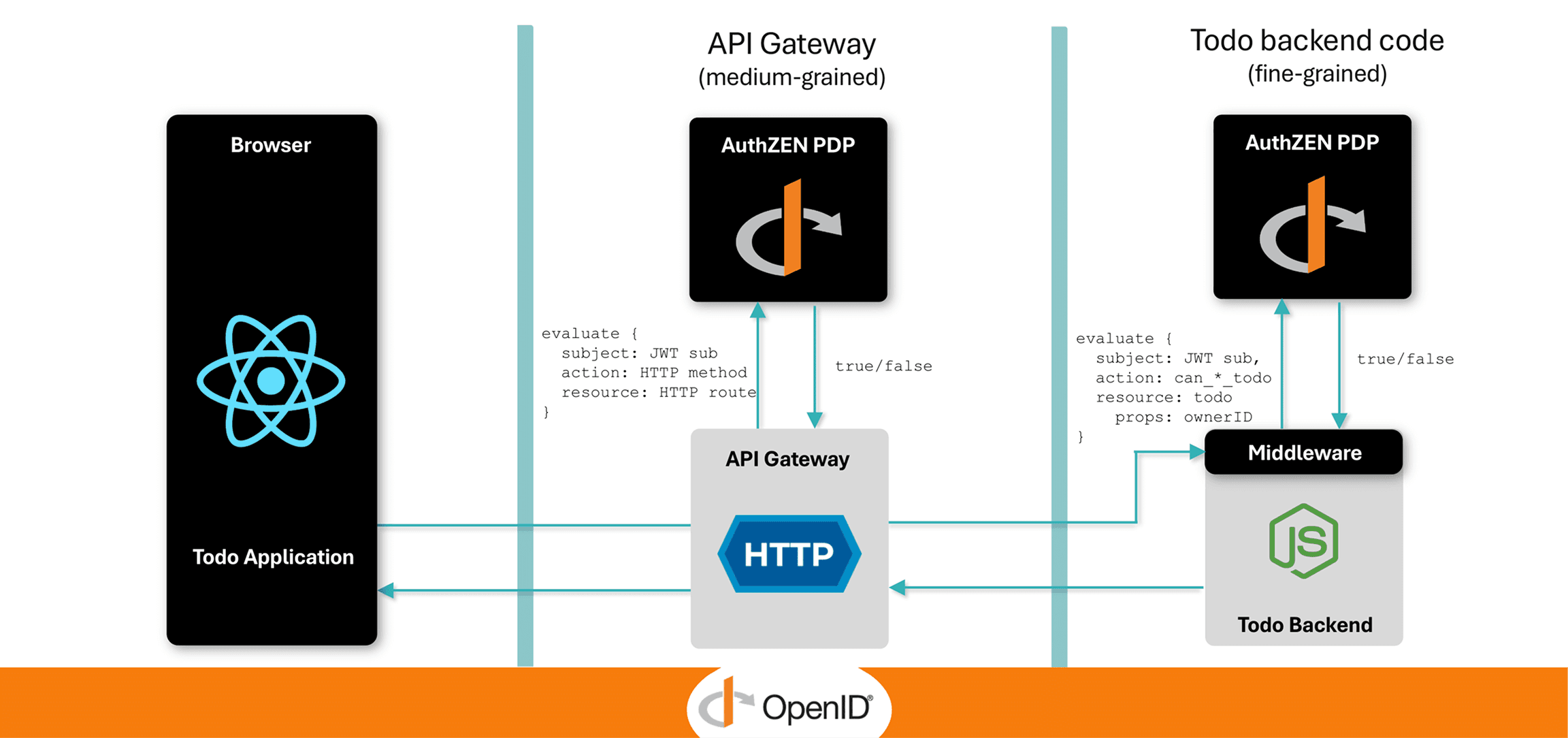
In short, minimizing lock-in comes down to using open technologies where possible, abstracting your code away from proprietary APIs, and pushing vendors, with your dollars and input, toward interoperability. It’s about maintaining flexibility as your needs evolve.
The evolving role of DevOps, and why identity matters
Modern architectures aren’t just about tech stacks, they’re also changing team roles and responsibilities. One theme the panel touched on is the evolution of DevOps and platform engineering in this new era.
Alex highlighted workload identity as a pressing challenge for DevOps teams. As systems incorporate more automation, microservices, CI/CD pipelines, and now AI agents, the number of non-human identities has exploded. Think of all the service accounts, API keys, CI jobs, and containers in a cloud-native system - there might be dozens of machine identities for every human user account. Each of these identities needs to be authenticated and authorized properly, yet many organizations don’t have a solid strategy for managing them. Alex noted that we’re on the “precipice of an explosion of AI agents” interacting with systems in unpredictable ways. Without giving each service or agent a unique identity, there’s no way to trace or control what it does - a security nightmare.
The solution is to treat non-human principals as first-class identities in your IAM system. That means issuing credentials (certs, tokens, etc.) to services and managing their lifecycle (provisioning, rotation, revocation) just like user accounts. “Without identity, you can’t do anything else,” Alex said - you can’t enforce policies or audit activity if you don’t know exactly which service is calling what.
Closely related is controlling what those identities are allowed to do. A leaked API token or an over-privileged service account can be just as damaging as a compromised user login. That’s why fine-grained, contextual authorization is increasingly critical. Authenticating a service is not enough; just because a workload presents valid credentials doesn’t mean it should have free rein. Every request needs to be checked against policies (who or what is allowed to do this?) with context considered. For example, an AI agent might be restricted to certain data or operations. Tools like Cerbos help by allowing teams to define and enforce these rules consistently across all services.
Check out our ebook “Securing AI agents and non-human identities in enterprises” for a practical roadmap to putting guardrails around NHIs in your stack, with Zero Trust principles at the core.
Another shift for DevOps is the growing need for software engineering skills in infrastructure. Paul noted that in years past, a sysadmin might get by with bash scripts and manual configs, but now everything is “infrastructure as code.” He pointed to new tools like Pulumi - infrastructure in general-purpose languages, and Dagger - CI pipelines as code, as examples of this next-gen approach. These tools offer great flexibility but require treating ops code like software, with version control, testing, and sound design.
“If you’re not a strong coder, you need to get coding – fast – or you’ll be left behind,” Paul said. The era of clicking around UIs or hacking together shell scripts is giving way to writing proper programs to manage infrastructure. Even Kubernetes YAML is being supplemented by controllers/operators that embed custom logic.
For DevOps teams, this means adopting software development best practices: use Git for all infrastructure definitions, do code reviews for changes, write tests for your infrastructure code and pipelines, and continuously sharpen your programming skills.
Finally, dealing with legacy systems remains part of the job. Legacy applications won’t disappear overnight when new tech arrives. Modernizing or integrating these older systems with cloud-native services can be challenging, so a pragmatic approach is key. The panel’s advice: use patterns like the strangler fig (gradually replace parts of a legacy system with new services) or run legacy and modern components side by side with clear APIs between them. And always consider why you’re moving a legacy system to the cloud or a new stack - do it for specific benefits such as cost, scalability and new capabilities, not just because of hype. Alex noted that some companies even pulled certain systems back on-prem after the cloud didn’t meet their needs.
Best practices aren’t dead, but pragmatism rules
Amid all the talk of new tech, the panel also reflected on timeless software engineering principles. One question was whether concepts like clean code, Clean Architecture, SOLID, and design patterns still matter. The answer was a resounding yes, with caveats. A solid grounding in these principles is as valuable as ever, but they’re guidelines, not hard laws. You have to apply them judiciously. Sometimes two principles may conflict, or a strict design pattern might over-complicate things. Good engineering is about judgment and balance.
The panel also discussed prototyping and MVPs. In a startup or fast-moving project, speed is often the priority. Paul noted that if you’re whipping up a proof of concept, you might not follow every best practice, and that’s okay, as long as you refactor later. The danger is if that quick-and-dirty code becomes the foundation of your product without any cleanup.
Thus, a key skill is knowing when to refactor and invest in code quality. Victor recommended an incremental approach: once a feature is working, take a little time to tidy the code and structure. This prevents a pile-up of tech debt. Kenneth added that many developers try to design the perfect, ultra-generic solution upfront. But you simply can’t foresee everything. “The more generic you make it, the more code you write, and the harder it is to refactor later,” he observed. It’s often better to solve the problem in front of you in a straightforward way, then generalize when new needs emerge.
Engineering leads should also allocate time for refactoring and maintenance, whether via dedicated cleanup sprints or a portion of each sprint, to pay down technical debt. Otherwise, as Romano warned, the quick-and-dirty approach will “bite you in the long run.” Over-engineering can waste time too - it’s about finding the right balance. Aim for a solution that’s appropriate for today’s requirements, and evolve it as needed.
Continual learning and final thoughts
The world of software architecture is ever-evolving, and staying current is part of the job. The panelists shared a few favorite resources for keeping up with trends: Paul recommended Rawkode Academy for hands-on cloud-native learning, Victor listens to the Fallthrough podcast (formerly Go Time) for developer insights, and Alex pointed to the Software Engineering Daily podcast for cutting-edge case studies. Romano reminded us not to neglect the classics - books by Martin Fowler or Gregor Hohpe’s The Architect Elevator still offer valuable lessons in architecture and IT leadership.
Ultimately, building the future of application architecture requires marrying new technologies with tried-and-true wisdom. There’s plenty of excitement around what’s possible - AI everywhere, hybrid clouds, microservices done right. But also a recognition that fundamentals like clear design, proper abstractions, and strong security practices are more important than ever. The path forward is about balance: embracing innovation while staying grounded in first principles.
If you’re ready to explore these topics further, a great next step is to check out our ebook on securing non-human identities (service accounts and more), which digs deeper into managing machine identities and fine-grained access control. And if you’d like to see how Cerbos can help implement these ideas in your own stack, feel free to check out the solution, or schedule an engineering workshop. We’re always happy to help you put strong security guardrails in place so you can build with confidence as you navigate the future of application architecture.
FAQ
Tagged in





