
2026 is testing CISOs and CIOs like never before. Through countless conversations with security leaders, from coffee chats at conferences to deep-dive strategy sessions, I've witnessed how the CISO role has evolved into a high-wire act. Every conversation reveals the same reality: the job has never been more demanding. Today’s CISOs must navigate stricter regulations, pervasive cloud deployments, relentless threats, and even the risks and opportunities of AI.
The CISOs we speak with consistently tell us they feel at risk. According to one industry survey, 70% of CISOs feel at risk of a material cyber attack in the next 12 months. Despite growing confidence in some defenses, the pressure is unrelenting - from boardrooms expecting security to enable the business, to teams stretched thin by talent shortages.
At Cerbos, these aren't abstract statistics. We work with security leaders grappling with these issues every day. In this article, I'll break down ten critical challenges CISOs shared with us in 2026 and offer pragmatic solutions to overcome them. In each case, the goal is not only to protect the enterprise, but to enable it: effective security should be a business enabler, not a bottleneck.
TL;DR:
Compliance pressures are intensifying. Governments worldwide are enforcing data privacy and cybersecurity regulations with massive fines for violations, making continuous compliance a top business risk. CISOs must embed compliance into operations from the start rather than bolt it on later.
Zero Trust is now operational. What was once a buzzword is now an imperative. Implementing true Zero Trust architecture requires strong identity foundations and centralizing authorization, but legacy systems and user experience trade-offs make execution challenging.
Hidden access controls create blind spots. Many organizations still hard-code authorization logic in each application, leading to inconsistent policies and an audit nightmare. Without a centralized, auditable view of who can access what, CISOs have a serious control gap. Externalizing authorization into a unified service is key to visibility and agility.
Complex, distributed environments strain security. Multi-cloud and hybrid work environments dissolve the traditional perimeter. Misconfigurations abound, an estimated 70% of cloud breaches stem from misconfigured access controls. CISOs need consistent policy enforcement and automation across diverse infrastructure.
Tool sprawl and alert fatigue undermine defense. Enterprises use dozens of security tools - an average of 76, by one count, creating siloed data and overwhelming analysts with noise. Consolidating the security stack and integrating workflows is essential to improve efficiency and reduce human error.
Below, we dive into each of the ten challenges in detail and discuss how to address them, from policy and compliance issues to architectural and team dynamics considerations.
1. Keeping pace with mounting compliance requirements

CISOs can keep pace with rapidly evolving compliance mandates by building security governance into day-to-day operations, but this is easier said than done. Regulatory compliance isn’t optional in 2026. It’s table stakes. Major frameworks like GDPR, HIPAA, PCI DSS, and new digital operational resilience acts are enforcing strict standards with teeth. Violations lead to painful consequences.
For example, EU regulators have levied massive fines under GDPR; British Airways faced a £183 million fine after a breach for failing to safeguard customer data. Overall, non-compliance costs companies about 2.7× more than meeting requirements, when factoring in disruption, legal fees, and reputation damage. In short, the cost of doing nothing is far higher than the cost of compliance.
The challenge is that compliance today isn’t a one-time project - it’s a continuous process. CISOs must track a patchwork of global laws and industry standards, ensure policies and controls map to each requirement, and produce evidence on demand for auditors. This means having audit-ready logs of every access decision, up-to-date risk assessments, and documented workflows for things like user access reviews and change management.
Strong data governance is critical as well. If you don’t know where sensitive data lives or who has access, you can’t possibly stay compliant. In my experience, successful CISOs treat compliance as an ongoing program woven into product development and IT operations, rather than an afterthought.
Solution: Embed compliance into the fabric of IT and development from the start
This begins with clear policies that align to regulations and are enforced through automated controls. For example, implement fine-grained access controls that enforce least privilege by design, and use policy-as-code so that changes are tracked and testable.
Log everything: authentication and authorization events, administrative actions, data exports, and policy changes. These tamper-proof logs will save you during audits.
Many organizations are now adopting continuous compliance monitoring; automated checks in CI/CD pipelines and cloud configurations that flag drift from compliance baselines.
Crucially, pick tools that make compliance easier. An externalized authorization solution like Cerbos can provide a central point to manage access policies and generate audit trails for who accessed what and why.
The right platform can map your access rules directly to regulatory controls, for instance, tying a GDPR data access rule to a specific policy ID - simplifying evidence gathering.
Finally, foster a compliance-aware culture. That means training engineering teams on secure coding and data handling, and establishing a Change Advisory Board or similar process to evaluate changes for compliance impact before they go live. When compliance is baked into daily processes and technology choices, it becomes much more achievable, and far less likely to come back to bite you in the form of fines or breaches.
For more details on maintaining compliance, refer to this guide.
2. Implementing Zero Trust at scale

Implementing Zero Trust at scale requires strong identity foundations, architectural support, and executive commitment to see it through. For years, “Zero Trust” was a strategic mantra. Now it’s an operational reality. The core idea is simple: trust nothing and verify everything, whether it’s a user or a service, inside or outside the network.
In practice, this means shifting from network-based security to identity-based security. Your authentication needs to be rock-solid (think phishing-resistant MFA and unified identity providers), and your authorization needs to be fine-grained and contextual on every request.
The challenge is that many enterprises have a patchwork of legacy systems and incomplete implementations. Network perimeters have effectively dissolved; assets sit across multiple clouds and SaaS platforms, employees are remote, and applications are highly distributed. Relying on VPNs or IP addresses for trust is a non-starter.
The industry has thankfully converged on standards for identity - SAML, OAuth 2.0/OIDC for users, emerging frameworks like SPIFFE for workload identity.
But identity alone isn’t enough: a common blind spot in Zero Trust programs is authorization. Too often, organizations secure network access and authenticate identities, but then inside applications, the logic controlling what each identity can do is scattered and hard-coded. This decentralization makes a true Zero Trust posture impossible, because you can’t centrally answer “who should have access to what?”.
As one CISO put it in a Gartner Annual Survey Report: “There are challenges to implementing Zero Trust for user access - trying to balance the user experience and productivity, while strengthening security.”
Achieving Zero Trust means not just locking down network lanes, but also refining roles and permissions so that a compromised account or service can’t freely roam.
Solution: Establish identity and access management as the core of your security architecture
Start by inventorying all identity providers, directories, and authentication flows in use, consolidate where possible for consistency. Roll out strong MFA everywhere, and address MFA fatigue with risk-based authorization.
Next, tackle the authorization layer: treat authorization as a distinct service rather than app-specific code. By externalizing authorization to a Policy Decision Point, you gain a centralized brain enforcing policies across all your applications. This makes it feasible to answer auditors, or your own team, when they ask “Who can access sensitive customer record X?.” You can query one system or repository of policies rather than diffing dozens of apps. Choose an authorization solution that supports both role-based and attribute-based access control, so you can implement the principle of least privilege in a nuanced way (e.g. allow action Y only if user is in role X and data is in region Z).
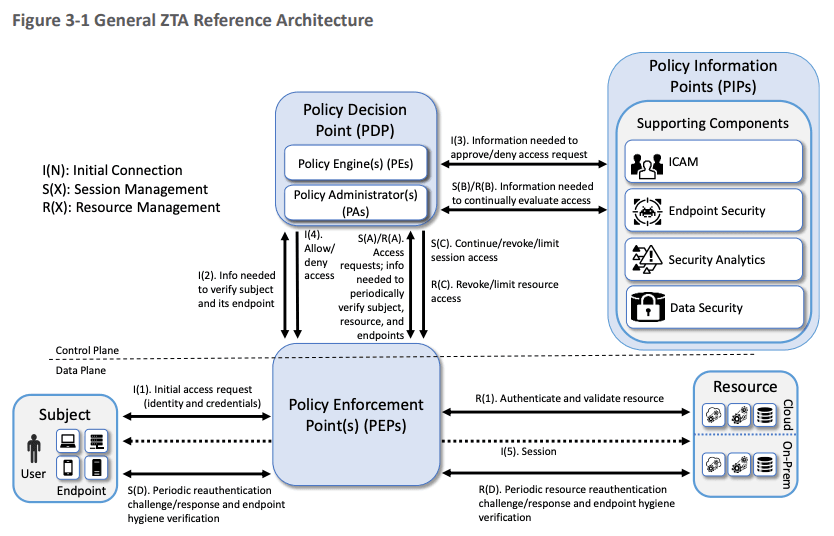
Source: NIST Special Publication 1800-35, Implementing a Zero Trust Architecture
Crucially, plan for the user experience impact of Zero Trust. Repeated authentications and access checks can frustrate users if done clumsily. Mitigate this by using adaptive and risk-based policies. For instance, skip additional prompts if a device is managed and on a known network, but require step-up authorization for sensitive transactions. Communicate the “why” to employees so they understand security friction is protecting the business.
Finally, treat Zero Trust as a phased journey. Start with quick wins like enforcing single sign-on and MFA enterprise-wide and segmenting critical systems, and gradually tighten policies.
Metrics help here: measure things like percentage of sensitive resources covered by your new authorization service, or reduction in implicit trust connections. When done right, Zero Trust actually reduces the blast radius of incidents dramatically. If an attacker compromises one app, fine-grained authorization prevents them from moving laterally into other systems. It’s a long-term program, but one that pays off by turning security from a perimeter problem into a manageable access governance problem.
3. Hidden authorization logic putting your data at risk
When authorization rules are buried in application code and differ by team, it creates security blind spots and inconsistent enforcement. This is one of the most underrated challenges CISOs face.
Many organizations have grown organically, with each engineering team implementing its own access controls within their app or service. The result is a tangle of “shadow” authorization policies that nobody has a unified view of. From a risk management perspective, this is unacceptable. If you, as a CISO, cannot confidently answer “who can access our critical data or functions,” you have a serious control deficiency.
Unfortunately, that’s the reality in a lot of enterprises. An audit would discover permissions that were granted years ago in some module, or an app with a hard-coded admin backdoor. The lack of centralized policy visibility makes it nearly impossible to audit permissions or quickly adjust to new threats or compliance needs.
I’ve seen this problem firsthand. In one case, a fintech company needed to enforce a new privacy regulation which meant limiting access to certain personal data. Because their authorization logic was siloed in each microservice, what should have been a simple policy update turned into a month-long engineering fire drill across ten teams.
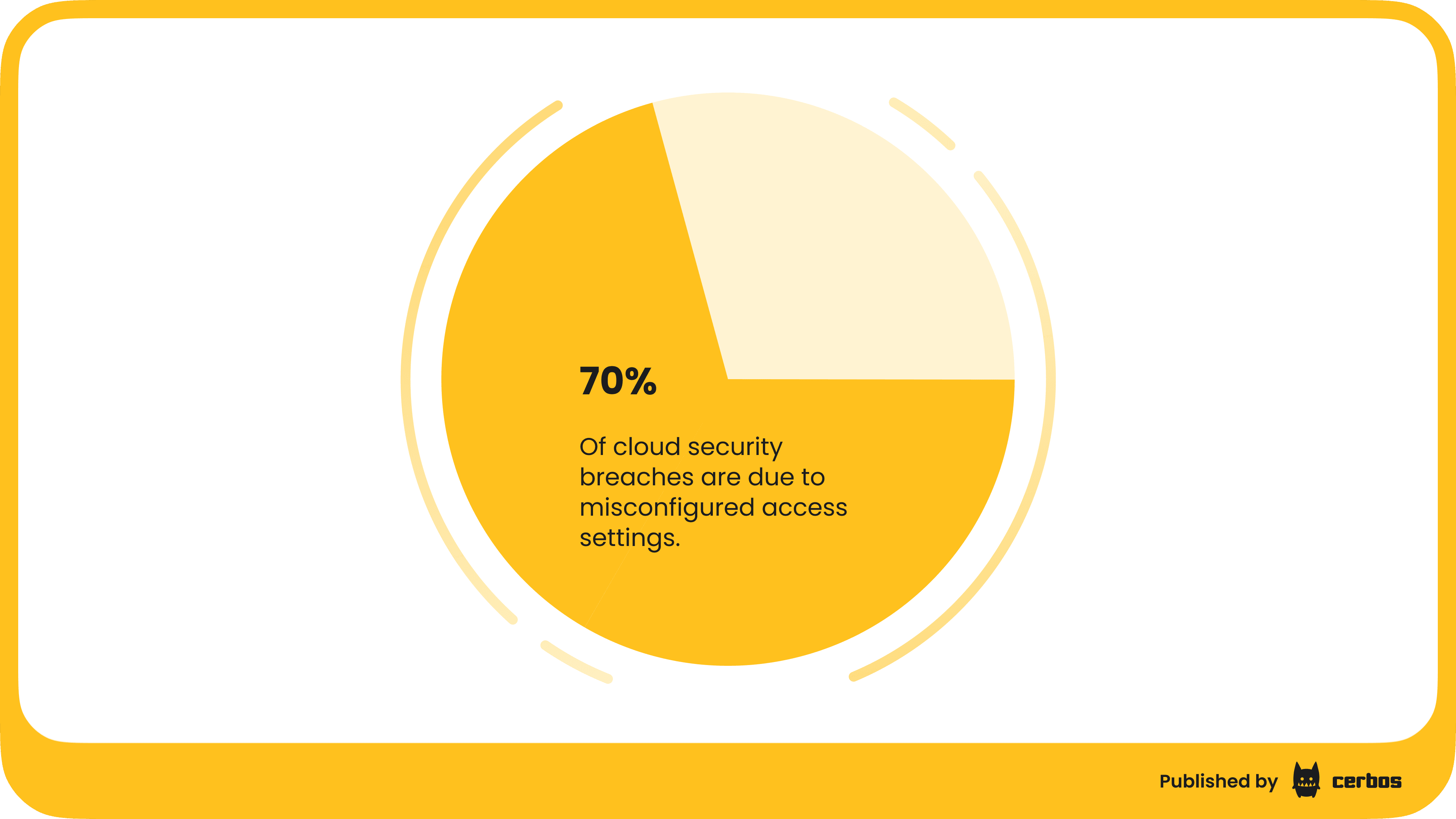
This fragmented approach also tends to produce errors. A subtle logic mistake in one service’s permissions can open a hole that no one notices. In fact, misconfigurations and logic flaws in access control are a leading cause of breaches. One study found nearly 70% of cloud security breaches are due to misconfigured access settings. When every app is an island of authorization, the chances of a mistake somewhere skyrocket.
Solution: Externalize and unify your authorization policy management
The only scalable solution is to treat authorization as a centralized service rather than ad-hoc code. Practically, this means deploying a policy engine that all your applications query for “can user X do action Y on resource Z?” decisions. Your developers replace the hard-coded checks with a call to this service. By doing so, you transform authorization from a black-box within each app into a transparent, centrally managed control plane.
All your policies live in one place, written in a human-readable language, where security teams and developers can collaborate on them. This makes it so much easier to audit and update policies. For example, if a new law requires a change, you update one policy repository instead of twenty applications.
When choosing a solution, look for one that provides fine-grained visibility and auditing. A good authorization solution will log every decision with details: who made the request, what policy was evaluated, and why the decision was allow or deny. These logs are gold for compliance and forensic analysis.
Also important is a policy testing framework. Treat your authorization policies as code that can have unit tests. Before deploying a policy change, you can run tests to ensure you didn’t inadvertently open a hole or break a legitimate use case. Solutions like Cerbos even support a “playground” and CI/CD integration for policy tests, so you catch mistakes early.
By centralizing and automating authorization in this way, you not only close the security gaps but also enable faster changes. A policy tweak can be rolled out globally in minutes, whereas in the old model it might require coordinating multiple dev teams and release cycles.
The net effect is stronger security and agility. In summary, if your authorization logic is currently hiding in each app, it’s time to shine a light on it. Centralize it, standardize it, and you’ll eliminate a huge source of risk and complexity.
4. Securing multi-cloud and hybrid environments is complex

The sheer scope and diversity of today’s IT environments make unified security control extremely challenging. Most organizations now operate in a multi-cloud world, they might have workloads in AWS, Azure, and GCP, plus a smattering of SaaS apps and perhaps on-premises data centers. Employees are working from everywhere, accessing resources over the internet.
This modern architecture delivers agility, but from a security standpoint it’s a nightmare if not managed properly. You’re dealing with multiple disparate platforms, each with its own security configurations, logging formats, and nuances. Ensuring consistent security policies across all of them is difficult. It only takes one misconfigured S3 bucket or one forgotten server to create an entry point for attackers.
The complexity is evident in cloud misconfiguration statistics. We already noted that a majority of cloud breaches come down to misconfigurations - these are often not cutting-edge zero-day hacks, but simple mistakes like leaving storage open or mismanaging an access key.
The Capital One breach is a famous example: a misconfigured firewall in a cloud deployment allowed an attacker to steal millions of records. That misstep cost Capital One $80 million in regulatory fines and an even larger hit to remediation costs and reputation.
Cloud providers offer dozens of security controls (IAM roles, security groups, key vaults, etc.), and keeping track of all those across multiple clouds stretches any team thin. On top of that, hybrid environments mean you may have legacy systems without modern controls that still need protection.
Another factor is the speed of change. In cloud environments, new services spin up and down constantly. Here, think of containers, serverless functions. Traditional security approaches like monthly vulnerability scans or static firewall rules can’t keep up. Attack surfaces emerge and disappear in hours. This dynamic nature requires equally dynamic security measures - continuous monitoring, automated remediation, and policy-as-code that applies wherever your workloads go.
Solution: Invest in unified visibility and automation across your environments
First, embrace a cloud security posture management solution or equivalent that aggregates configuration data across all clouds. You need a single pane of glass that can tell you “these 5 assets are exposed to the internet” or “these 3 storage buckets contain sensitive data and are misconfigured.” Many breaches happen because nobody noticed a change in security posture until it was too late. CSPM tools can auto-detect issues and even auto-remediate simple misconfigs like auto-closing an open port and alerting the team.
Next, extend your Zero Trust principles to the multi-cloud. This means strong identity federation. Integrate your IAM so that you’re not managing totally separate identities in each cloud. If possible, use a common SSO for user access to cloud consoles and a unified directory for entitlements.
Also, deploy a consistent authorization layer for your applications - recall challenge #3. If each service in each cloud calls the same authorization service, you can enforce consistent rules enterprise-wide. For network-level security, consider software-defined solutions like a service mesh that can enforce encryption and authentication between services across clouds.
Crucially, automate what humans can’t keep up with. Use Infrastructure-as-Code templates for cloud deployments with built-in security guardrails. For example, codifying that any new storage bucket must have encryption and not be public. Then use scanners to check IaC for policy violations before deployment. Some organizations implement automated cloud compliance checks in their CI pipelines, essentially unit tests for infrastructure configurations, to catch risky configs early.
Finally, don’t forget the basics amid the complexity: asset inventory and segmentation. It’s hard to protect what you don’t know you have. Implement tagging and discovery processes so every VM, container, and microservice is accounted for in an inventory. Segment your cloud networks and accounts by environment and sensitivity. If dev/test environments are isolated and a credential leaks, attackers can’t jump to prod. Isolation limits the impact.
Yes, multi-cloud security is complex, but a combination of centralized monitoring, consistent identity/authorization, and automation can tame the chaos. The goal is to make a heterogeneous environment feel like one logical security domain from the CISO’s perspective.
5. Security blind spots due to too many security tools

Often, an overabundance of security tools can ironically reduce visibility and efficiency for a CISO’s team. Enterprises have accumulated a tool for every problem: SIEMs, endpoint agents, network monitors, CASBs, DLP solutions, IAM platforms, cloud security platforms. The list goes on.
In theory, more tools mean more coverage. In practice, each generates its own alerts and reports, and they rarely talk to each other out of the box. The result is alert fatigue and fragmented data. It’s not uncommon for critical warnings to get lost in the noise or for different tools to give a conflicting picture of the environment.
There’s a striking statistic: on average, enterprises use 76 different security tools to protect their networks. Imagine the overhead of managing 76 dashboards and data streams. Not only does this require significant manpower and expertise, but it also increases the chance of human error. Analysts end up doing a lot of manual correlation - copying data from one system to investigate in another, writing one-off scripts to glue outputs together. This is time-consuming and error-prone.
It’s telling that despite more tools, breaches continue to happen; having 10 overlapping tools doesn’t help if none of them give a complete view. Blind spots emerge in the gaps between tools. For example, you might have a great network IDS and great endpoint detection, but if an attack uses an encrypted channel, maybe neither tool sees the full picture without integration.
Moreover, all these tools often come with their own agents and performance impacts, and they produce a high volume of alerts. Security teams are inundated - one survey found analysts can only investigate a small fraction of the thousands of alerts they receive daily. Unhandled alerts become another form of blind spot.
One Fortune 500 company’s security team admitted that an alert did go off but was ignored, “buried beneath 5,000 daily false positives,” which allowed an intrusion to slip through unnoticed. This real-world example shows how alert overload can undermine security when important signals get lost in the noise
And then there’s cost: the budget implications of dozens of vendors, many with overlapping capabilities, are significant. In tight budget environments, spending inefficiency here can hurt.
Solution: Consolidate and integrate your security tooling to streamline visibility
Start by taking inventory of all your security tools and mapping them to your core security functions, such as protect, detect, respond, recover. Identify overlap and underutilized tools. It may be possible to eliminate some and use one platform for multiple needs. Many modern security platforms, like extended detection and response - XDR, aim to bring multiple capabilities under one roof. If one solution can replace three while providing a unified data lake for threats, that’s a big win.
Integration is the other key. You don’t necessarily need a single monolithic product, but your tools should feed into a central analysis point. Often this is a SIEM or security analytics platform. Ensure that all critical logs and alerts flow into one place where correlations can happen. If you have a cloud-native environment, consider using cloud provider’s unified logging/monitoring plus a layer that normalizes data across sources. Investing in a security data lake or an Open XDR approach can allow you to apply detection logic across all your data rather than in silos.
Additionally, apply automation and orchestration to handle the deluge of alerts. Define playbooks for common alerts so that software can automatically gather context or even remediate issues without human intervention. For example, if an endpoint alert shows malware and your SOAR can automatically isolate that host and create a ticket, that’s one less manual task. This reduces the pile of trivial or repetitive alerts, letting analysts focus on the truly critical ones.
Finally, measure and tune. Track metrics like mean time to detect and respond, or the percentage of alerts investigated. If those metrics improve after consolidating tools, you’re on the right track. Also solicit feedback from your security engineers and analysts - the people in the trenches. They will tell you if a certain tool causes more trouble than it’s worth, or if integrating two systems saved them hours.
The end goal is a cohesive security ecosystem: fewer consoles to check, unified dashboards for the CISO, and end-to-end visibility of attacks. By reducing tool sprawl, you actually increase your team’s focus and the clarity of your security picture.
6. The need to move from “Shift left” to “Shift down” security

One of the freshest insights from the 2025 ISC2 Security Congress is the call for security teams to evolve beyond the traditional “shift left” approach. Shifting left - embedding security earlier in the development lifecycle - is still vital. But forward-thinking CISOs now realize it’s time to “shift down” as well: embed security deeper into the platforms and frameworks that developers use, so that security is an integral part of the infrastructure itself. As Google’s Phil Venables put it during his keynote, security should be built in, not bolted on.
Venables’ message highlights that today’s prevalent model of “artisanal security”, where each team hand-crafts bespoke controls, simply doesn’t scale for modern enterprises.
When every development squad has to implement its own authentication, access control, input validation, etc., you end up with inconsistent protections and lots of developer toil. Skilled developers spend cycles reinventing security features from scratch, and often getting it wrong or creating gaps, instead of focusing on business logic. This artisanal approach burdens developers and results in fragmented, bolt-on security controls that are hard to manage across “massive, complex systems.”
Shifting down flips this script by engineering security into the platform layer. Instead of pushing ever more security responsibilities onto individual developers, the organization’s technology stack provides security as a built-in service.
Think of it as moving from craft security to industrial security. In practice, this means security controls are delivered through shared frameworks, libraries, and cloud platforms that developers automatically inherit. For example, if your cloud platform and app framework provide strict TLS/mTLS, hardened authentication and fine-grained authorization, input sanitization, and audit logging by default, developers don’t need to be security experts to build safe applications - the environment has security baked in. They “inherit a higher degree of standard control from the environment” by default.
The benefits of this shift-down model are huge. Developer productivity soars because teams aren’t constantly re-implementing security primitives; common threats like SQL injection or XSS are stamped out centrally in the framework.
Security consistency improves because controls are standardized enterprise-wide rather than varying by team. And when new vulnerabilities or compliance requirements emerge, a centrally engineered fix or update in the platform instantly protects all services - a leverage that ad-hoc, application-level fixes can never achieve. Notably, Google Cloud found that when they enabled several security features by default across their platform, 99.5% of customers left those protections on - proving that secure defaults, once built-in, tend to stick.
In short, “shift down” means security at scale through industrialized, autonomic mechanisms instead of one-off efforts.
Solution: Champion a platform-centric security strategy
Invest in internal developer platforms or cloud services that offer “secure by default” capabilities, so dev teams get security controls without extra effort. Start identifying where your organization is relying on “artisanal” solutions (e.g. every team writing its own authorization code or secret management scripts) and move those into shared services. This may involve closer collaboration between the security engineering team and the platform/DevOps teams to build security features into the core tech stack.
Aim for “control and policy as code” where possible: organizations that implement their policies as code and embed them in infrastructure are “in massively great shape” and able to scale security effectively.
In a shift-down model, security becomes a shared foundation: developers can innovate freely on product features, while the underlying platform, maintained by security and SRE teams, quietly enforces critical guardrails.
Cerbos enables this shift-down approach by making one important security control - authorization - autonomic and standardized across all services. Instead of every application developer crafting custom role checks or permission rules, which is an artisanal nightmare, Cerbos provides a fine-grained, policy-as-code authorization service that applications simply call into.
It externalizes authorization from individual apps, offloading that burden to a central, hardened policy engine. This means every service in your architecture shares a common, reusable authorization layer governed by uniform policies. Developers no longer need to write bespoke access control logic at all; they inherit robust enforcement as a service.
The result: significantly reduced dev toil, consistent access controls enterprise-wide, and the agility to update policies in one place. By adopting Cerbos or similar “security as a service” components as part of your platform, you’re effectively “shifting down” security - building it into the infrastructure so it’s always-on and transparent to developers. (We’ll dive more into Cerbos in the conclusion.)
7. New threats that come with AI and automated systems

Generative AI and autonomous systems introduce novel security challenges, from data leakage to unpredictable agent behaviors. In 2026, nearly every organization is experimenting with AI in some form, whether that’s large language models like ChatGPT, AI code assistants, or autonomous “agent” software that can act on behalf of users. These bring tremendous opportunity, but also risk. In fact, 54% of CISOs believe generative AI poses a security risk to their organization. There are a few dimensions to this challenge:
Data exposure. AI models often require large training datasets or real-time data inputs. If not carefully controlled, sensitive data could be inadvertently fed into third-party AI services (e.g. an employee pasting customer data into a chatbot to get an answer). We’ve already seen companies ban or restrict use of public AI tools for this reason. Moreover, LLMs themselves can regurgitate training data. If a model was trained on your sensitive info and then someone queries it cleverly, it might spill secrets it shouldn’t.
AI-powered attacks. Attackers are leveraging AI too. We’re seeing AI used to craft more convincing phishing emails at scale, to automatically find vulnerabilities or write exploit code. Deepfakes and synthetic media threaten to erode trust in authentication (imagine a fake audio of your CEO instructing finance to transfer money). AI can also rapidly mutate malware to evade detection, basically an “offense at scale” scenario.
Autonomous agents and non-human identities. This is a new frontier. You might have AI agents that can execute actions like creating documents, updating records, even making transactions. These agents operate at machine speed and can have a wide scope. If one goes rogue, either through malfunction or malicious manipulation, the damage could be quick and extensive.
For example, an AI Ops agent with the power to spin up servers could be tricked into deploying a fleet of mining bots, or an AI customer service bot might start leaking private data if prompt-injected incorrectly. The rise of autonomous AI agents increases the urgency for robust authorization - these non-human identities need strict policies governing what they can do. We can’t rely on hard-coded rules or manual oversight; it must be automated and fine-grained.
Solution: Apply security principles to AI and treat AI systems as high-value assets
Start with governance: establish clear policies on acceptable AI use. For instance, define what data can or cannot be fed into external AI APIs, and educate your employees on this. Monitor traffic to popular AI endpoints to detect policy violations. Some companies route AI queries through a proxy to log and filter sensitive content. If using third-party AI SaaS, scrutinize those vendors for security controls - do they isolate your data, it is used for training, will they delete it on request, how is it stored?
For AI-developed code or configurations, implement additional review steps. AI can speed up coding, but it can also introduce vulnerabilities at scale. Have a process where any AI-generated code is reviewed with a security mindset, maybe even using AI-based code analysis as a second pair of eyes.
In terms of AI-driven attacks, bolster your defenses with AI too. Many modern security tools incorporate machine learning to detect anomalies, like unusual login patterns or transaction fraud. Keep your staff updated on deepfake trends and consider implementing verification steps for any requests that involve sensitive actions (e.g., a policy that large fund transfers always require a live video call, not just an email approval, to counter deepfake audio/email). Essentially, raise awareness that seeing isn’t always believing when it comes to digital content.
For autonomous agents and non-human identities which might be running in your environment performing tasks, enforce the principle of least privilege strictly. If you have an “AI service account” that can perform certain functions, ensure it has the minimal access required and nothing more.
Use an externalized authorization service such as Cerbos to evaluate every action such agents take, just as you would for a human user. Policy-driven authorization becomes critical here: you might have rules like “AI agent X can read from database Y but not write to it” or “AI process can execute these API calls but with rate limits”. With a central policy engine, you can govern AI actions uniformly and log them for audit. It’s also wise to implement kill-switches or monitoring for AI agents - if they start behaving unexpectedly or outside approved bounds, have an automated way to halt them and alert the team.
As Ty Sbano, CISO of Webflow, put it: “We’re all becoming managers of agents. We need to understand who’s responsible for what those agents do and how we govern that responsibly.”
In other words, these AI-driven processes are a new class of identities to manage, and require the same rigor, if not more, as human users. By weaving AI oversight into your existing security framework (identity management, data loss prevention, monitoring), you can reap the benefits of AI while mitigating the novel risks it brings.
8. The cybersecurity talent shortage

CISOs must get creative in hiring, training, and augmenting their teams, because the cybersecurity talent gap is a long-term reality. It’s no secret that skilled security professionals are hard to find. In the U.S. alone, there are over 500,000 cybersecurity positions unfilled, and globally the number is in the millions.
This shortage means two things: first, it’s difficult to scale your security team with the growth of threats, and second, your existing team is likely overworked and at risk of burnout. In fact, about 33% of security professionals have considered changing careers due to burnout.
The CISO role itself is no cakewalk either - one report noted 32% of CISOs have considered leaving their job due to stress and regulatory pressure, and the average tenure of a CISO is only ~2 years. High turnover can compound the talent problem, as you lose institutional knowledge.
With lean teams, CISOs have to carefully prioritize where to focus human effort. Many are turning to managed security service providers or outsourcing certain functions like 24x7 SOC monitoring, to make up for staff shortages. Others invest heavily in automation, as discussed in challenge #5, to let one analyst do the work that might have required three people in the past. But there’s no silver bullet - security is a labor-intensive domain and you do need smart people who can make judgment calls.
Team dynamics are also crucial. In a tight talent market, retaining your best people is as important as hiring new ones. That means paying attention to workload to prevent burnout, providing growth opportunities such as training and new challenges so they don’t feel stuck, and fostering a positive culture. Security can be stressful; celebrating wins and reinforcing the mission can help keep morale up. Talented individuals often leave if they feel their work isn’t appreciated or if they’re constantly under water with alerts and no relief in sight.
Solution: Adopt a multi-pronged strategy. Nurture internal talent, leverage external resources, and use technology force-multipliers
First, look inward: sometimes the skills you need may already exist in your IT or engineering departments. Consider establishing a rotational program or training interested internal employees to move into security roles. People with aptitude in IT ops or software development can often become great security analysts or engineers with some targeted training. Upskilling your existing team through certifications and courses can fill skill gaps, and also boosts retention, as employees see you investing in their growth.
Next, streamline your operations to make the most of the people you do have. This means prioritizing ruthlessly. If you have limited staff, you may need to accept that some lower-risk areas get less focus while critical areas get full coverage. Develop a risk-based staffing model. For example, ensure you have incident response capability, since breaches can be existential threats, even if that means you have to minimally staff something like routine compliance checks which could be later automated or handled by other departments.
Use outsourcing strategically. Managed security service providers can take on tasks like around-the-clock monitoring, initial incident triage, or running your vulnerability management scans and reports. This doesn’t absolve you of oversight, but it can relieve pressure on your core team. If you go this route, treat the MSSP as an extension of your team: have regular touchpoints, SLAs for response, and ensure they understand your business context, not just the raw alerts.
Another approach is tapping into the security community. Encourage your team to participate in knowledge-sharing groups, local security meetups, or online forums. Sometimes answers to tough problems or leads on talent can come from community connections. Being visible in the community, say, presenting a case study at a conference, also helps attract talent to your organization by showcasing interesting work.
On the automation front, as discussed, try to offload repetitive tasks to scripts and tools. For example, if your analysts spend a lot of time provisioning access or pulling logs for audits, invest in automation or self-service tools for those tasks. Freeing even 20% of an analyst’s time by eliminating “busy work” is like adding 0.2 of a headcount.
Lastly, focus on retention just as much as recruitment. Engage your team in big-picture discussions so they understand how their work matters to the company’s mission - a sense of purpose can outweigh a higher paycheck elsewhere. Ensure salaries are competitive, yes, but also consider things like flexible work arrangements (remote work can help with talent since you’re not limited to one geography). Recognize accomplishments publicly to combat the often thankless nature of security. No news is good news doesn’t always feel rewarding. Burnout is real, so encourage using PTO, perhaps rotate on-call duties widely, and watch for signs of fatigue.
While the talent shortage won’t resolve overnight, CISOs who take a proactive approach in developing talent and optimizing workloads will be better positioned. By creatively augmenting your team and keeping them motivated, you can cover the most critical bases until the broader industry pipeline catches up (which might be years). Remember that a small, well-supported team can outperform a larger, poorly managed one. Quality over quantity is the guiding principle when people are your scarcest resource.
9. Surging software supply chain attacks

Attackers have discovered that targeting the software supply chain can yield huge rewards, leading to a surge in these types of attacks. Rather than directly hacking a well-defended enterprise, adversaries are increasingly going after weaker links, such as third-party software providers, open source components, or managed service partners that a target organization relies on.
By compromising one supplier, they gain access to many downstream customers. We’ve seen high-profile examples: the SolarWinds Orion breach, where an APT inserted malware into a software update that was then distributed to thousands of organizations, or attacks on open source libraries, like the event-stream npm package incident, where a popular library was taken over and booby-trapped.
Statistics back up the trend. Between 2021 and 2023, supply chain cyber attacks surged by 430%. Gartner analysts predicted that by 2025, 45% of organizations worldwide will have experienced a software supply chain attack, a threefold increase from 2021. These numbers underscore that this isn’t a theoretical risk but an almost expected event. The allure for attackers is clear: a single successful tampering of a widely used component can grant access to a multitude of victims, many of whom may not detect the intrusion until it’s too late.
Several factors contribute to this surge. One is the explosive growth of open source software usage. Modern applications are often more than 70% composed of open source libraries. While this is great for productivity, it means you’re implicitly trusting a vast, globally distributed supply chain of volunteer-maintained code. Attackers exploit this trust by injecting malicious code into libraries through compromised maintainer accounts or taking over abandoned projects.
Another factor is the increasing interconnection of services via APIs and third-party integrations. Companies might integrate dozens of SaaS providers; if any one of those is breached, it can be a pathway into your data. We also see sophisticated attackers targeting development tools themselves, like build servers, package repositories, container images, to plant backdoors upstream.
The challenge for CISOs is that you can have excellent security internally and still be compromised through a dependency you never even realized you had. Traditional security assessments and questionnaires sent to vendors sometimes aren’t enough, as vendors themselves might be unaware of backdoors in their products.
Solution: Harden your software supply chain and demand the same of your partners
Start with your own development pipeline: implement integrity checks and provenance for your code. For instance, use cryptographic signing for code and build artifacts, so that any tampering in transit is detectable. If you’re pulling open source dependencies, use package management tools’ features to pin versions and verify checksums. Consider using dependency scanning tools (Software Composition Analysis) as part of your CI process to flag outdated or vulnerable libraries.
Adopt the practice of Software Bill of Materials for your applications - essentially a manifest of all components and their versions. This not only helps you understand your exposure when a new vulnerability in a library is announced, but it can also be provided to customers to increase transparency. In fact, some regulations and large customers are beginning to require SBOMs from software providers. Internally, track SBOMs from your critical vendors too, if you can get them.
For third-party vendor risk, maintain a strong vendor management program in coordination with procurement and legal. This includes thorough security assessments of partners and suppliers. However, instead of just checklist compliance, try to assess their security posture in practice: Do they have a robust patching process? Do they segregate customer environments? How do they vet their own employees? Additionally, push key vendors to have a coordinated vulnerability disclosure program or at least to notify you if they experience a breach. Speed of awareness is crucial; if you only learn about a supplier breach from the news months later, the damage is done.
Network-wise, employ zero trust principles with third parties: just because a partner’s system connects to yours doesn’t mean it should have unfettered access. Use strong authentication, like certificate-based or SSO, for any integrations and restrict what data and commands those integrations can execute. Monitor data flows to and from third parties for anomalies, like a usually small integration suddenly transferring gigabytes of data.
Another key defense is to practice incident response drills for supply chain scenarios. Assume a critical library you use gets compromised and starts exfiltrating data - would you detect it? Maybe have a honeytoken (fake sensitive record) and monitor if it ever leaves the environment, indicating something fishy. Or simulate a breach of a contractor’s account that has VPN access: can your SOC quickly isolate that? Table-top these exercises with your team.
Ultimately, while you can’t eliminate all supply chain risk, since no one controls all their suppliers 100%, you can significantly reduce the blast radius. By increasing visibility through knowing what’s in your software, enforcing minimum security standards on partners, and architecting systems to fail safely so one component’s compromise doesn’t domino through the whole environment, you can make your organization a much harder target in this realm.
Attackers are opportunistic - if you and your peer companies all present a solid front, they’ll have fewer easy opportunities to exploit the software webs that tie businesses together.
10. Communicating cyber risk to the business
CISOs should translate technical risks into business language, using clear metrics and stories that resonate with the board and executives. One of the most crucial, yet challenging, parts of a CISO’s job is communication upward and outward.
It’s easy to get mired in tech jargon or worst-case scenarios, but the board and C-suite need to understand security in terms of impact, likelihood, and readiness. The days of just saying “we blocked X million attacks” are over; leadership wants to know so what? How does cyber risk threaten our strategic objectives? Are we spending appropriately to mitigate those risks?
A frequent challenge is justifying the security budget. Security can be seen as a cost center, with success defined by nothing happening, which paradoxically can make it harder to argue for resources when you’re successful. There’s a stat that, on average, only 9% of a company’s IT budget is allocated to security. If the board doesn’t grasp the rationale, they may balk at increasing that number.
Additionally, new regulations, like recent SEC rules in the US, are putting cyber risk squarely on the agenda of boards and even requiring disclosures of cybersecurity readiness. This puts CISOs under more scrutiny to quantify and communicate their risk posture.
Another communication hurdle is expressing uncertainty and incident response in a calm, factual way. For example, telling the CEO “there’s a critical vulnerability in one of our systems, but here’s our plan to address it and the likely impact” is much better than a panicked dump of technical details. The board doesn’t expect zero risk; they expect that you know your risks and have a plan.
It’s useful to remember that many executives are not deeply technical. Analogies and straightforward comparisons help. I have seen analogies like, “Our cybersecurity program is like the immune system of the company - we can’t prevent every germ from entering, but we aim to quickly detect and neutralize threats before they cause serious damage.” Framing in terms of health, finance, or safety - domains they handle regularly - makes cyber less abstract.
Solution: Speak the language of business and focus on risk management, not just technical measures
Start by aligning your communication with business objectives. For each major cyber risk, identify what business asset or process it ties to. For instance, instead of saying “SQL injection vulnerability in our web app,” say “There’s a risk someone could manipulate our customer database via the website, potentially exposing customer data, which would impact trust and incur breach costs.” Then quantify it: “This type of breach could cost us an estimated $X in fines and lost business based on industry averages.” By couching it as a business risk (financial, reputational, operational), you fit into the same risk framework the CFO uses for market or credit risk.
Use metrics wisely. Executives love metrics, but only if they illustrate a trend or efficacy. Present a few key risk indicators: e.g., percentage of critical systems with multifactor authentication, mean time to detect/respond to incidents and how that’s improving, number of high-severity vulnerabilities open vs. last quarter. Show before-and-after of investments: “We spent $Y on a new email filtering system, and phishing click rates dropped by 60%, reducing likelihood of a breach.” Visuals like heat maps (likelihood vs impact of top risks) can be effective to summarize where the biggest concerns lie and how you’re addressing them.
Be honest and clear about incidents and readiness. If you had a minor security incident, it’s often better the board hears it from you proactively, with an explanation of how it was contained and lessons learned, rather than discovering it through rumor or after it grows. This builds trust that you have things in hand. Also communicate preparedness: for example, “We have an incident response plan, we conduct quarterly cyber drills, and we have cyber insurance for residual risk.” Board members feel more at ease knowing there’s a plan.
Storytelling can be powerful. Share brief anecdotes: “Last month our SOC team caught a targeted phishing attempt impersonating our CFO - because we had trained employees, an accountant reported it immediately and we prevented a potential fraud.” Real examples make the abstract threat real, but also highlight the value of security controls in place.
Finally, when asking for resources, tie it to outcomes. Rather than “we need $1M for XYZ technology,” say “Investing $1M in XYZ will reduce our risk of a customer data breach by improving our detection capabilities, aligning us with industry benchmarks (maybe mention a compliance requirement or peer doing similar). That’s cheaper than the $5M+ estimated cost of a breach of that data.” Framing cost/benefit in business terms helps non-security leaders make informed decisions.
In summary, effective communication is about contextualizing cyber risk as business risk. Replace technical jargon with impact statements, use numbers and stories to back it up, and always convey that cybersecurity is about enabling the business safely, not about saying “no” to everything. When the board and executives see you as a risk manager who speaks their language, you’ll get the support you need to build resilience - and you might even extend that average CISO tenure by forging a strong partnership with the business.
The Cerbos solution: Policy-driven authorization enabling “Shift down” security at scale
After examining all these challenges, a clear pattern emerges: security must be unified, scalable, and built into your technology stack. Not sprinkled on top. That is the “shift down” model.
Cerbos delivers that model for authorization. Cerbos is a policy-based authorization solution for the software enterprises are building, that plugs into your architecture - not as an afterthought or add-on, but as a foundational service. It enforces fine-grained and contextual access control across applications, APIs, workloads, and AI agents, and is designed for Zero Trust environments and AI-powered systems.
Cerbos’ authorization system consists of three connected components:
-
Policy Decision Point. An open source engine that evaluates authorization logic and returns decisions to client services.
-
Enforcement Point SDKs. Lightweight SDKs and libraries that integrate those decisions directly into applications and APIs.
-
Policy Administration Point. A managed control plane for authoring, testing, deploying, and auditing authorization policies at scale.
All three architectural components work together, enabling externalized authorization. The PDP is the runtime. The SDKs are the enforcement path. The PAP (Cerbos Hub) is the control plane for everything around authorization management. By deploying Cerbos, organizations adopt the “shift-down” philosophy in the crucial domain of access control.
Instead of treating authorization as scattered code snippets within each app, Cerbos centralizes it as a reusable service. Every application can offload its permission checks to Cerbos via simple API calls, and Cerbos handles them according to globally defined policies, written as code. This means security rules are enforced consistently everywhere by default, reflecting a secure-by-design approach.
Built-in, not bolted-on: Cerbos lives alongside your apps as part of the core platform. It’s not a library the developer might choose to ignore; it’s a standard component of the architecture. This empowers a “shared fate, not shared responsibility” model internally, akin to what cloud providers like Google promote. In other words, your central platform team, with Cerbos, takes on the heavy lifting of authorization, so individual developers aren’t left on their own to implement and secure it. Each team can thus operate securely by default, leveraging a common control plane rather than reinventing controls independently.
The outcome is greater agility for development teams - they can build features faster when they don’t have to code permission logic from scratch or wait for security reviews on every change. It’s also easier to adjust to new requirements; since Cerbos policies are code, you can update an access rule once and instantly propagate it across all services.
Another major benefit is uniform enforcement of Zero Trust principles. Cerbos treats authorization as a service, so you can enforce least-privilege access at every layer: APIs, microservices, databases, even AI systems. Because policies are externalized, an identity’s permissions are checked on each request, consistently. This directly supports Zero Trust’s mandate that no request is implicitly trusted. And if you discover a new threat or policy change, you update it in one spot - Cerbos will propagate it across all enforcement points instantly. No more hunting through code to plug a gap. This central management also means there are no “shadow” access rules hiding in some legacy app; everything is visible in the Cerbos policy repository.
Auditability and compliance improve as well. Cerbos provides full policy versioning, change logs, and decision audit trails out-of-the-box. Every access decision can be recorded, and every policy change is tracked. This level of visibility makes passing audits and meeting regulations far simpler, because you have a single source of truth for “who can access what” and a history of how that was determined. In a world of increasing governance pressure, having authorization centralized and transparent by design is a huge advantage.
Cerbos looks forward: it aligns with and is a founding member of emerging standards like AuthZEN, an OpenID Foundation effort to standardize authorization interfaces. Why does this matter for a CISO? It means Cerbos is future-proofing your investment - as standards mature, Cerbos speaks the common language. You won’t be locked into a proprietary approach; instead you’re part of an interoperable ecosystem. AuthZEN is basically doing for authorization what OAuth did for authentication, and Cerbos is leading the charge to ensure compatibility. This reduces vendor lock-in and assures you that Cerbos is built on secure, community-vetted principles.
Finally, Cerbos preserves autonomy with alignment. Teams get the autonomy to develop in the languages and architectures they prefer - Cerbos offers language-agnostic APIs and SDKs - while still aligning with a unified security policy. This means product squads aren’t hamstrung by a one-size-fits-all library or endless security checklists; they simply integrate with the Cerbos service and continue working in their domain.
Security teams, meanwhile, gain autonomy from constant firefighting and code reviews of authorization logic. They can focus on defining high-level policies and let Cerbos consistently enforce them.
This dynamic creates a virtuous cycle of agility and safety: developers move fast under a protective umbrella of standardized controls, and CISOs gain confidence that critical policies are enforced uniformly across the organization.
In summary, Cerbos embodies the “shift-down” approach for one of the most fundamental security controls - authorization. It addresses many challenges we discussed: it gives you policy visibility, aids in Zero Trust by centralizing least-privilege enforcement, eases compliance with audit logs and testable controls, boosts velocity by decoupling policy changes from code, and is ready for AI-era authorization (governing non-human access with contextual policies). It’s a cohesive solution that lets you enforce the right policies consistently, no matter how your systems evolve.
By adopting a solution like Cerbos, a CISO can confidently say: We have a unified handle on who can do what in our enterprise, and we can adapt those rules at the speed of business. That is a huge step toward conquering the security challenges of 2026 and beyond.

Planning to implement externalized authorization? Start with our 10-chapter guide for a structured approach to this transformation.
If you want to dive deeper into implementing and managing authorization, check out Cerbos, or speak with a Cerbos engineer.
FAQ
Tagged in





