
Externalized authorization is quickly becoming a core part of enterprise architecture. At IAM conferences and in conversations with engineering teams, we’ve seen growing interest in policy engines. It’s a great sign that the industry is maturing and looking for scalable, secure ways to manage access.
Both Open Policy Agent (OPA) and Cerbos are open-source policy engines, that help teams externalize authorization logic from application code, but they take very different approaches. OPA is a general-purpose policy engine used for a wide variety of policy decisions, predominantly in the infrastructure layer (eg. Kubernetes) and more recently as well as in the application layer. Cerbos is a purpose-built authorization engine for application- and API-level access control, focused on simplifying fine-grained permissions.
When we built the first version of Cerbos, we began with OPA as the underlying decision engine. It was a great starting point, but as our needs evolved and as we saw what developers truly needed, we hit limitations that led us to build our own custom decision engine optimized for authorization checks. That transition became a foundational part of our product evolution and shaped how Cerbos works today.
In this article, we will break down the differences between Cerbos and OPA across policy language, developer experience, architecture, performance, and policy management. We will also show the strengths and limitations of each solution and discuss practical trade-offs.

Policy language
Cerbos
Cerbos policies are defined in a declarative YAML format (or JSON) that will feel familiar to most developers. Rather than requiring a new programming language, Cerbos leverages YAML schemas to express authorization rules, with concepts for principals (users), resources, roles, and actions.
This human-readable policy-as-code approach makes it easy to write and review access rules. For any conditional logic, Cerbos uses Google’s Common Expression Language (CEL) inside the YAML policies.
- CEL expressions allow defining boolean conditions (e.g., ensuring the resource's owner matches the requesting user) in a concise, readable way.
- Because policies are essentially configurations, they can be version-controlled and edited without deep programming knowledge.
Design of the Cerbos policy language prioritizes simplicity. A typical Cerbos rule might say that users with role X can perform action Y on resource Z, optionally adding a CEL condition for context-specific checks (such as time of day, resource ownership, or value of a field).
This constrained language model covers common RBAC/ABAC/ReBAC/PBAC needs without forcing developers to learn a new syntax. The trade-off is that Cerbos’s policy language is less free-form than a general programming language - it is optimized for access control use cases.
In practice, this means most authorization requirements can be captured with straightforward YAML definitions, and developers are not bogged down by complex syntax. Cerbos’s use of YAML + CEL offers a gentle learning curve for policy authors while supporting complex rules when needed.

OPA
OPA uses a domain-specific language called Rego for writing policies. Rego is a declarative logic programming language inspired by Datalog, which allows teams to express policies as rules that derive a decision from given inputs.
This approach allows developers to represent arbitrary conditions, iterate over data, and enforce complex logic using Rego. However, this flexibility comes with a steep learning curve.
- Rego’s syntax and paradigms are not commonly used in everyday application development, so teams often need significant training to become proficient.
- Writing an OPA policy means writing code (textual rules) in Rego, which many developers find difficult to learn if they’re unfamiliar with declarative logic languages.
In Rego, policies are written as rules that evaluate to allow/deny decisions or other structured outputs. Because OPA is not tied to a specific domain, like user permissions, the policy author must define the schema and structure of inputs (e.g. what “user” or “resource” means in context). This gives OPA versatility - it can be used for anything from access control to pod security policies - but it also means there is no built-in high-level abstraction for common authZ scenarios.
Everything is expressed in terms of Rego rules over JSON data. In summary, OPA’s Rego provides great expressiveness for policy logic at the cost of greater complexity. It’s a declarative query language that may feel heavyweight for teams that only need role/attribute-based access rules.
The learning curve and unfamiliar syntax remain key considerations when adopting OPA’s policy language.
Developer experience
Cerbos
Before building Cerbos, we spoke with developers, IAM leads, and security teams to understand their needs. Cerbos was designed with those insights in mind, aiming to make integration and policy management as straightforward as possible.
The developer experience focus is a core part of Cerbos’s philosophy:
-
Cerbos offers simple APIs and SDKs in multiple languages (Go, Java, Node.js, .NET, Python, and others) so that developers can check permissions with a single function call in their code. For example, using the Cerbos SDK, a developer might call a method like
isAllowed(principal, resource, action)and get an allow/deny decision without worrying about the underlying logic. -
This high-level API (specifying who is doing what on which resource) abstracts away the complexity of policy evaluation. It means developers do not need to interact with the policy engine at a low level; they can rely on Cerbos to handle policy enforcement, scaling, and even logging behind the scenes.
Beyond the API, Cerbos provides tooling that fits with development workflows.
- Policies, being YAML files, can be edited in any IDE and kept in source control alongside application code.
- Cerbos supports IDEs for code completion and syntax checking when writing policies.
- Cerbos offers a CLI and testing utilities to validate policies, has a unit testing framework that allows users to do full matrix testing, as well as an interactive policy editing UI - the Cerbos Playground, for collaboration.
When running Cerbos, it automatically generates detailed decision logs and explanations for each authorization check. This means that if a request is denied, developers or DevOps teams can inspect the Cerbos audit logs to see exactly which rule caused the denial and why, greatly simplifying debugging of permission issues.
Cerbos offers a developer-friendly experience by providing easy integration, familiar policy syntax, and built-in support for testing and troubleshooting. We’re proud of how far the developer experience has come, and we’re continuously improving it.

OPA
OPA’s developer experience is geared toward those comfortable with infrastructure-as-code practices. Since OPA policies are code, developers work with them similarly to how they work with application code: editing text files, using Git for version control, writing unit tests (opa test), and so on.
This policy-as-code model lets experienced engineers integrate OPA policies into CI/CD pipelines and treat them like any other codebase. For example, a team might require that any policy changes in Git trigger automated tests and deployment to OPA agents, ensuring that policies are validated and reviewed.
However, for the average developer or less-technical stakeholder, OPA can be challenging to use directly.
- There is no high-level SDK call akin to Cerbos’s
isAllowedout of the box - typically, an application interacts with OPA by querying it, often via a REST or gRPC API call to a local OPA sidecar. While language SDKs (Go, JS, Java, Rust) are available, they essentially wrap these low-level calls. This means the developer must still define rule names (e.g., allow), construct and send the correct JSON input, and manually parse the decision response. - Setting up OPA in an app involves writing Rego policies and establishing how data (e.g. user attributes) is fed into OPA.
- Debugging OPA policies usually requires using OPA’s built-in query tester or verbose trace logs, which is a more manual process compared to Cerbos’s built-in explanations.
- Moreover, OPA lacks a native, user-friendly interface for policy authors. It’s largely a developer’s tool - policy changes require editing Rego files. Non-engineers or less technical team members typically cannot write OPA policies without training, which can limit who can contribute to authorization rules in an organization.
While there are VS Code extensions for Rego, a playground for trying out policies, and community libraries for various languages to interact with OPA, the overall developer experience with OPA is best for teams that have the bandwidth to learn Rego and build tooling around it. It’s flexible and scriptable, but not as immediately approachable as Cerbos.
Architecture
Cerbos
Cerbos follows an architecture tailored to application- and API-level authorization needs. At its core, Cerbos is a stateless Policy Decision Point (PDP) service that you can deploy alongside your application - either as a separate service, a sidecar container, or even embedded as a library in certain cases. Being stateless, each Cerbos instance doesn’t require its own database; it loads the policy files and uses in-memory evaluation for incoming requests. This makes Cerbos deployment quite flexible and lightweight - you can run it in a container on Kubernetes, on a VM, on-premises, or even on edge devices.
Many deployment models are supported:
- A central service model (one or a few Cerbos servers that all apps call into),
- A sidecar model (each app instance has a Cerbos proxy next to it),
- A serverless function (Cerbos PDP in a Lambda, etc.),
- An embedded library in Go apps or via first-class support for a WebAssembly runtime, depending on latency and isolation requirements.
Cerbos’ architecture allows it to scale horizontally easily: you can spin up more Cerbos instances behind a load balancer to handle more load, since no instance holds unique state.
Cerbos’s internal engine is purpose-built for evaluating access control policies. The policy model (principal, resource, actions, conditions) is baked into the architecture, meaning that Cerbos knows how to interpret an incoming request with a principal’s attributes and a resource’s attributes against the loaded policies.
This specialization streamlines the decision process. The Cerbos PDP exposes APIs (HTTP and gRPC) for querying decisions, and these APIs are uniform - you send a decision request describing the actor and resource, and get back an allow/deny, plus, optional metadata like reasons or obligations.
Because Cerbos is stateless, operational complexity is low: there’s no need to manage distributed state or consensus. Policies can be updated by simply deploying new policy files or pointing Cerbos to a policy repository. Cerbos can watch a directory, Git repo, or cloud bucket for policy updates, or you can push updates via an API, depending on your setup.
We designed Cerbos’ architecture to be application-centric - it acts as a microservice that any app can call to get authorization decisions, running wherever your app runs, and focusing solely on that task.

Cerbos is being used to secure AI agents and microservices, including API gateways, LLM agents, and data filtering layers. With Cerbos Synapse, that reach extends to infrastructure layers like API gateways, data platforms, and messaging systems too. Because Cerbos enforces context-aware, stateless decisions, it is ideal for scenarios where AI agents or services need to operate within strict access boundaries. For example, API gateway integration allows Cerbos to filter unauthorized requests before they reach backend services - a critical feature in AI architectures where misuse or oversharing of data can cause security breaches.
OPA
OPA’s architecture is built for general-purpose, distributed policy enforcement. OPA is essentially a policy decision engine that can be co-located with any software that needs decisions. A common architectural pattern is to run an OPA sidecar next to each service instance that needs authorization checks. Each OPA instance keeps the relevant policies and data in memory, ensuring that decisions are low-latency and local. This distributed deployment means that every service has its own policy evaluator, so, like Cerbos, there is no single point of failure or central bottleneck for policy decisions. OPA itself is stateless with respect to long-term storage; again, like Cerbos, it stores policies and data in memory and you feed it updates as needed.
The big difference is that OPA doesn’t come with a predefined data model for requests - you can decide what JSON structure to send to OPA and what output to expect, usually you define a rule that produces an allow boolean or similar. This allows OPA to be inserted into many contexts: as an Envoy ext-authz filter, as a Kubernetes admission controller (OPA Gatekeeper), inside CI/CD pipelines for config checks, and more.
However, this flexibility comes at the cost of increased integration effort. Because OPA lacks a standardized data model, each integration typically requires custom schema design, input normalization, and output parsing—all of which can lead to duplicated effort, inconsistent policy outcomes, and higher maintenance overhead across teams.
Deployment and integration of OPA can take a few forms.
- It can run as a separate daemon that your application calls via a REST API, or via a Go API if you embed OPA as a library in a Go program.
- It can be compiled to WebAssembly (WASM) and embedded directly into applications written in any language that supports WASM.
- In Kubernetes environments, a popular usage is Gatekeeper, where OPA is paired with custom resources to enforce policies cluster-wide.
- In microservice architectures, you might see dozens of OPAs deployed, one per service or host, all kept in sync with the latest policies.
OPA’s design assumes you will manage distribution of policy to these instances (more on that in the management section). Because each OPA instance is independent, scalability is achieved by adding OPA instances wherever needed.
The flip side is that OPA by itself is a lower-level component - you have to design how it fits into your system. Will your app call OPA on each API request? Will OPA intercept requests at the proxy layer? These decisions are left to the implementer.
In summary, OPA’s architecture is flexible and cloud-native: it’s a small engine you deploy alongside your code to offload policy decisions, enabling distributed policy enforcement at scale.
Performance
Cerbos
Cerbos’s focused design allows it to achieve high performance for authorization use cases - the Cerbos engine can evaluate permission checks very efficiently.
In fact, after we moved away from the general OPA engine and created a custom engine, Cerbos achieved up to 17× faster decision evaluations compared to our earlier OPA-based implementation. In real terms, this means a Cerbos policy check typically takes only a fraction of a millisecond of CPU time. For a web application that might perform hundreds or thousands of permission checks per second, this optimization can reduce overall request latency and CPU load significantly.
Cerbos also optimized memory usage and startup time by not carrying any extra baggage beyond what’s needed for authZ decisions. The engine loads only the policy rules relevant to the defined resource types and roles, keeping the footprint small.
In practical scenarios, a single Cerbos instance can handle thousands of requests per second with minimal latency impact - often sub-millisecond per check. Because Cerbos is stateless and horizontally scalable, you can run multiple instances to parallelize the load without coordination overhead.
Another aspect of performance is data fetching. Cerbos keeps the PDP stateless by design and never makes external calls during evaluation. You can pass all context in the API request directly, or use Cerbos Synapse to automatically enrich requests before they reach the PDP. Synapse connects to identity providers, databases, and custom sources via connectors, fetching identity, resource, and relationship data at decision time with configurable distributed caching. Because enrichment happens in a separate layer, the PDP stays fast and predictable with no surprise network calls.
This contrasts with some authorization systems that might pull in external data during a decision and slow things down. One of the most common pieces of feedback we hear from users is that Cerbos delivers fast and predictable performance for authorization. That’s exactly what we aimed for when building our solution - targeting real-time user permission checks where every millisecond counts, and both benchmarks and user reports show it delivers on that promise.

OPA
In practice, each OPA decision is evaluated in-memory (against the policy and data it has loaded), so the typical overhead is small, often on the order of tens to hundreds of microseconds for simple policies.. The local or library-based architecture means that calls to OPA are usually a local function call or localhost HTTP call, avoiding network hops. This means OPA can be used in latency-sensitive paths without a major penalty.
That said, the actual performance of OPA depends on how complex your Rego policies are and how much data OPA has to chew through. Simple RBAC-style policies in Rego will evaluate fast. But if you write very complex rules or have megabytes of JSON data loaded into OPA for context, evaluation might be slower.
OPA does have advanced features like partial evaluation, similar to Cerbos, and prepared queries, which can reduce evaluation latency and CPU cost. Partial evaluation lets you pre-compute static sections of the query to produce an input-specific policy, thereby generating a simplified policy for repeated use.
In terms of memory footprint, OPA is fairly efficient in pure evaluation, but running many OPAs (one per service instance) means each has its copy of policies and data in memory. This is usually fine, but in memory-constrained environments, it’s a consideration. In contrast, a single central Cerbos might use memory more sparingly by sharing one loaded policy set. In summary, OPA provides good performance and can scale out by deploying more instances, but a targeted solution like Cerbos can outperform it for the specific case of application authZ due to custom optimizations. This difference will become very evident at extreme scales or under heavy load, where every bit of efficiency helps.
Policy management and administration
Cerbos
Managing policies in Cerbos is very straightforward, thanks to the product's focus on user needs and provided tooling. Since Cerbos policies are plain files (YAML/JSON), you can manage them using your normal code workflows: store them in a Git repository, code-review changes, and track versions. Cerbos facilitates this by supporting multiple storage backends for policies - you can load policies from the local filesystem, a Git repo, a cloud storage bucket, or a database, whichever fits your deployment model.
In a simple setup, you might bake the policies into your application container image or mount them via a volume. For more dynamic scenarios, Cerbos can watch a Git repository or be instructed to pull updated policies periodically, so that all running instances get the latest rules. This makes distributing policy updates across environments easier.
For auditing and administration, Cerbos has built-in features to log every decision and even every policy change. Every Cerbos PDP can output audit logs detailing which access requests were allowed or denied, including contextual information. These logs can be aggregated for compliance audits or debugging security incidents. This is one of the features security, compliance, and leadership teams appreciate most, as it gives them greater control and peace of mind.

Cerbos also provides an admin API, and through the commercial offering - an authorization management solution called Cerbos Hub, to manage policies centrally.
Cerbos Hub is a hosted control plane that organizations can use to collaborate on policy editing, continuous test running, and deploying policies from development to production. It offers capabilities like centralized policy management of multiple PDP instances, unified audit log viewing, and a policy testing playground. This means that a team can use a SaaS control plane interface to update policies and push them out to all their Cerbos nodes, rather than dealing with each instance separately. The clarity and auditability of Cerbos policies also help streamline security reviews and demonstrate internal controls during audits.
Even without Cerbos Hub, Cerbos’ open source core includes CLI tools and an interactive policy editor (for example, a VS Code extension or the ability to run a local UI) to simplify writing policies. Importantly, Cerbos’s approach allows not just developers but also security engineers or system administrators to participate - the YAML syntax is approachable enough that with a little training, it’s readable by less technical stakeholders, and the existence of a UI and documentation lowers the barrier for collaboration.
For platform leaders or compliance executives, this translates into lower onboarding and ramp-up costs, less reliance on specialist roles, and faster policy iteration cycles. With Cerbos, engineering teams can move quickly and autonomously without introducing compliance or operational risk, enabling organizations to deliver features faster while meeting governance requirements.
It’s important to mention that Cerbos also goes far beyond traditional role-based models to support adaptive multi-tenancy. Instead of forcing B2B platforms into static roles like "Admin" or "Editor", Cerbos enables teams to model each customer's unique organizational structure, custom roles, and internal permissions - without rewriting code. This flexibility is essential for SaaS providers scaling into enterprise markets, where customers expect software to reflect their own hierarchy, not the vendor's limitations.
Cerbos also centralizes policies across all identity types, including users, services, and non-human identities like AI agents. For AI workloads, Cerbos acts as the safety layer that contains and governs the actions of autonomous systems, ensuring every request adheres to the principle of least privilege. Enterprise buyers rely on these controls to mitigate risk, meet compliance requirements, and trust that access is enforced consistently at every layer of the stack.
In terms of maintenance overhead, Cerbos aims to be a “deploy and forget” component: once integrated, it requires minimal babysitting. There are no complex databases to maintain, and health checks mostly boil down to ensuring the service is up and has the latest policies. The stateless nature also simplifies versioning and rollback - if something goes wrong with a new policy, you can revert the file in Git and redeploy or instruct Cerbos to reload, without dealing with migrations or corrupted state.
Users have noted that Cerbos is one of those things “that just works,” with the team behind Cerbos being very responsive (24/7 support) if any issues arise. The combination of operational stability and quality support is a big reason why teams trust Cerbos to power critical authorization decisions at scale.
Cerbos is built to scale from small teams to complex enterprise environments. It supports multi-region deployment, centralized policy control with Cerbos Hub, fine-grained audit trails, and full API-driven policy CI/CD. Enterprises choose Cerbos not just for ease-of-use, but because it meets their governance, security, and performance requirements at scale.
Features like multi-tenant policy segregation, enterprise SSO support, and structured audit logging make Cerbos ideal for regulated and high-scale environments. Several Cerbos customers have replaced in-house or commercial solutions like OPA+Styra for these very reasons.
OPA
OPA, by design, provides only the policy engine, leaving policy management up to the user, or third-party tools. This is a conscious choice to keep OPA agnostic and flexible, but it means that out-of-the-box, OPA doesn’t include a centralized UI or automatic distribution system for policies.
Instead, it exposes Management APIs that you can use to build your own control plane. For example, OPA can be configured to periodically download policy bundles from a remote HTTP server. Many OPA deployments use this model: you package your Rego policies, and any JSON data, into a bundle file and host it on a service, and each OPA instance is configured to pull updates from there. This way, when you update the policy bundle, say, by committing to a Git repo and having a CI job build a new bundle, all OPAs will fetch the new version.
Similarly, OPA can emit decision logs to a remote endpoint of your choice. An organization might run a centralized log collector, or use a SaaS logging platform, and configure each OPA to POST every decision (allow/deny and related info) to that endpoint. This provides an audit trail, but again it’s on the user to set up receivers and storage for those logs. OPA’s management API also has a status endpoint to report health and bundle version, which a control plane can use to monitor if OPAs are up-to-date.
In practice, companies that adopt OPA at scale often either build an internal control plane or use a commercial service. Open-source users of OPA have also crafted their own solutions: some use configuration management or service mesh integrations to distribute policy files, others integrate OPA policy updates into application deploy pipelines. The key point is that OPA gives you the hooks to manage a fleet of policy agents, but it doesn’t dictate how you should do it. This can be a positive if you want full control (for example, if you want to integrate policy deployment with your existing GitOps process), but it can be a negative if you were expecting a plug-and-play admin UI or a one-click sync of policies across all agents.
Regarding multi-tenancy and organization-wide governance, OPA can handle multi-tenant data by scoping data per tenant in the policy, since you can load data for different tenants into OPA’s memory and separate via conditions. But there’s no built-in concept of multi-tenant policy isolation aside from what you implement in Rego or via separate OPA instances.
Monitoring OPA instances in production, checking they’re all running the latest policy, for instance, is another operational task; OPA can report its status, but you’ll need to aggregate those reports. In summary, managing OPA in production involves more effort in building the pipelines and tools around it. You get good flexibility: you can tie policy updates to your exact workflows. On the other hand, the administrative experience is more involved. Non-technical users will likely not interface with OPA directly at all - they might only consume reports or request features from the engineers managing OPA. Everything from policy authoring to distribution to auditing is oriented around engineers and code processes.
Certain organizations are willing to accept this for the benefit of OPA’s versatility. For organizations looking to enforce fine-grained, auditable access control across application stacks, APIs, AI agents, and service-to-service infrastructure, this level of DIY management becomes a liability - not a strength. Cerbos offers a unified approach to policy management that serves the needs of both engineering teams and enterprise buyers: from securing non-human identities to implementing zero-trust controls across microservices, Cerbos simplifies what OPA leaves as an exercise for the implementer.
It’s often this management overhead, and the earlier mentioned learning curve, that guide companies towards using OPA for broad infrastructure policy enforcement, and Cerbos for application- and API-level authorization where ease of management is a higher priority.
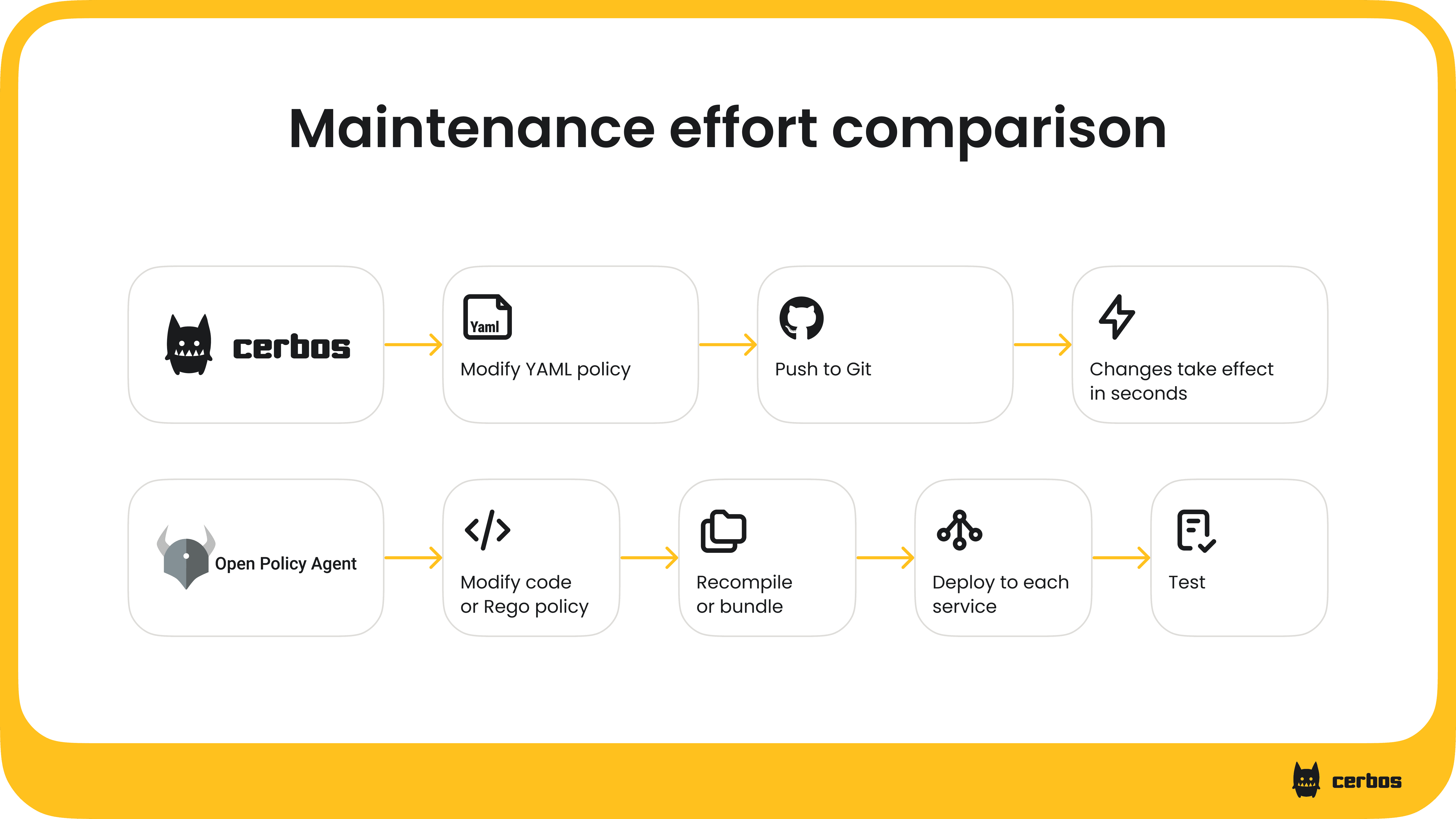
To summarize, let’s look at a quick comparison of OPA and Cerbos on key aspects.
Overview and key differences between Cerbos and OPA
| Aspect | Cerbos | OPA |
|---|---|---|
| Use case focus | Purpose-built for application and API-layer authorization (fine-grained RBAC/ABAC/ReBAC in apps, APIs, AI agents, and gateway interfaces). With Cerbos Synapse, that extends to infrastructure layers like API gateways, data platforms, and messaging systems. Cerbos is well-suited for protecting AI agents, RAG pipelines, and authorizing based on either human or non-human identities across strict data access boundaries. | General-purpose policy engine for any kind of policy (not just authorization) - used for infrastructure, Kubernetes, microservices, as well as application logic. Not specialized for app business logic by default. |
| Policy language | YAML + CEL (declarative config). Policies are written in YAML with conditions in CEL expressions. Familiar format with a low learning curve; no new programming language needed. | Rego DSL (declarative code). Policies are written in Rego, a Datalog-like language. Very flexible and expressive, but has a higher learning curve and unique syntax. Policies can return arbitrary data structures, not just booleans. |
| Policy model | Policy-as-data approach: policies are written as declarative and opinionated YAML with a defined structure. Cerbos has built-in support for common authorization models (RBAC, ABAC, ReBAC, PBAC, role hierarchies, tenant isolation, etc.), which means less boilerplate. The policy outcome is always an allow/deny decision (plus any additional request context), providing clarity and consistency. | Policy-as-code approach: you write rules in Rego. OPA doesn’t impose a specific domain model - which is flexible but means you must define your own schemas for roles, permissions, etc. There’s no first-class concept of “role” or “resource hierarchy”; you implement those via data and rules. |
| Deployment model | Flexible deployment: Can run as a centralized PDP service or as a sidecar next to your app. Supports REST and gRPC APIs, so any language/platform can query it. Cerbos instances are stateless; they load policy files into memory and evaluate requests purely based on input (context you pass). Horizontal scaling is straightforward. | Distributed deployment: Typically run OPA as a sidecar or library within each service that needs policy decisions (ensures low latency local decisions). Each OPA keeps policies/data in-memory. No central server by default (to avoid single point of failure). Requires a way to distribute and sync policies/data to all those instances (e.g. bundles, control plane). |
| External data & context | Cerbos keeps the PDP stateless by design. It never makes external calls during evaluation. You can pass all context in the API request directly, or use Cerbos Synapse to automatically enrich requests before they reach the PDP. Synapse connects to identity providers, databases, and custom sources via connectors, fetching identity, resource, and relationship data at decision time with configurable distributed caching. Because enrichment happens in a separate layer, the PDP stays fast and predictable with no surprise network calls. | Allows policy to load data in various ways: static JSON data files can be packaged with policies, or policies can call out via the http.send builtin to fetch data at runtime. This flexibility is powerful but means you must manage data updates (e.g. push new bundles or accept the latency of in-policy HTTP calls) and scale downstream systems for potentially unexpected load caused by a policy change. There is no dedicated enrichment layer: data fetching logic lives inside policies or in the bundle pipeline. |
| Performance | High-performance optimized for authorization: After initially using OPA internally, the Cerbos team built a custom engine, in Go, for authorization, yielding up to 17× faster decision evaluations than the earlier OPA-based version. In real-world use, Cerbos can handle thousands of authorization decisions per second with sub-millisecond latency. The engine is optimized in memory and CPU footprint for access control scenarios. | High-performance engine written in Go: In sidecar mode, decisions are local and avoid network hops. Typical decisions in milliseconds or less. However, evaluating Rego can incur overhead, especially for complex policies or large data sets, and in practice OPA policy evaluation might be slower for app authorization use cases compared to a specialized engine. |
| Observability & debugging | Cerbos provides detailed audit logs and explainability out-of-the-box: Every decision can include a reason and the policy rule that triggered it. This helps during development and in production audits to see why a request was allowed/denied. Cerbos also offers a CLI tool for policy testing and a Playground for trying out scenarios, which improve the developer experience. | OPA can produce decision logs (JSON structured logs of inputs/outputs) which you can aggregate. It also has a trace mode to debug how a decision was made, but the output is geared towards developers familiar with Rego. No built-in end-user-friendly explanations. |
| Developer experience | Developer-friendly: Simple SDKs for most languages and frameworks to make checks (pass principal, resource, action) or integrate directly via REST/GRPC. Built-in policy test tools and human-readable policy files. Detailed decision explanations and audit logs help with debugging and compliance. | Engineer-centric: Requires writing policies as code (Rego). Integration via REST API, Go library, or sidecar calls. Strong integration with DevOps pipelines (treat policies like code with tests, CI/CD). Steeper learning curve for developers; less accessible to non-engineers. |
Conclusion
Both OPA and Cerbos are effective in their domains.
The choice isn’t strictly “one is universally better than the other,” but rather which tool is better suited for the task at hand.
If you’re building or scaling a modern application with fine-grained access control requirements, Cerbos offers significant advantages in simplicity, performance, and maintainability. It's built to scale alongside your business. From regulated environments to AI-powered interfaces and APIs, Cerbos provides the performance, governance, and flexibility that enterprises demand.
OPA paved the way by popularizing policy-as-code, yet its generality can become a burden for teams that just need straightforward authorization in their apps.
Cerbos picks up where OPA leaves off, providing a developer-centric experience tailored to application- and API-level use cases, along with all the tooling and infrastructure needed to run it efficiently in production. It enables teams to implement granular roles and permissions in hours, not months, and evolve authorization logic safely as requirements change.
For technical guidance on migrating from OPA and Rego to Cerbos, refer to this blog.
If you’re looking to enforce fine-grained, contextual, and continuous authorization across apps, APIs, AI agents, MCPs, services and workloads - feel free give Cerbos a try. If you’re curious how Cerbos could fit into your architecture or have specific requirements to discuss, feel free to book a call with a Cerbos engineer for a free 1:1 session. With Cerbos, you can achieve robust, scalable authorization without the steep learning curve - empowering your team to focus on building features rather than reinventing access control.
FAQ
Tagged in





