
Every authorization decision depends on having the right data about who is making the request, a human or an AI agent, and what they are trying to access. Getting that data to the policy engine reliably and at scale is the part most teams end up building from scratch, repeatedly, across every service and team.
Today, we are introducing Cerbos Synapse to solve this challenge.
Cerbos Synapse is a built-in data integration and enrichment layer that gathers identity, resource, and relationship data from your existing systems and delivers complete context to the policy engine before every authorization decision. It completes the externalized authorization architecture: policy administration in Cerbos Hub, policy evaluation in the PDP, and now data integration handled by the platform rather than by each application independently.
Synapse integrates with systems like Envoy, Kafka, Trino, and Kubernetes using the authorization protocols they already support, so no custom adapters are required.

Now, authorization data can move from scattered application code to a governed platform layer, where context resolution becomes a shared, auditable capability instead of a per-team implementation.
The hidden engineering cost of authorization context
The quality of your authorization decisions is only as good as the data behind them. An access policy that checks whether a user can access a document needs attributes about that user (department, role, geography) and that document (ownership, sensitivity level, status).
Today, the application layer assembles this context independently. Every team that needs authorization decisions also writes the same data-fetching middleware: pull the user's profile from the IdP, look up resource metadata from a database, assemble a complete request, and send it to the PDP. This creates a structural problem. Authorization context is rebuilt in every service and scattered across systems, with no shared model or control point.

When the identity provider changes its API, or the organization migrates to a new IdP, every application that fetches attributes needs code changes. Authorization data flows are distributed across codebases, with no single place where security or compliance teams can audit how identity and resource attributes reach the policy engine.
Infrastructure systems make this worse. Each one has its own authorization protocol and requires a custom adapter to integrate. These adapters are separate integration projects, maintained independently, and evolve out of sync with the rest of the system.
It all adds up to repeated engineering effort. Teams spend time building and maintaining authorization plumbing instead of shipping features, while security and compliance lose visibility into how decisions are made.
Cerbos Synapse removes this overhead by centralizing how authorization data is fetched and used. Instead of rebuilding context in every service, the application sends a check request containing a user ID and nothing else. The data layer queries the identity provider, fetches the resource metadata, and delivers a complete request to the PDP. When the organization migrates to a new IdP, the change happens once in Synapse, not across every calling service. These are the gaps Cerbos Synapse addresses.
How Cerbos Synapse works
Cerbos Synapse is a self-hosted binary or container that sits in front of the Cerbos PDP. It runs either with a PDP bundled in the same process or against an existing PDP cluster. Applications that already call Cerbos continue making the same API calls.
The only infrastructure change is routing traffic through the data layer instead of directly to the PDP. OpenTelemetry instrumentation spans the full request path, so platform teams get distributed traces, cache hit rates, and extension latencies without instrumenting application code.
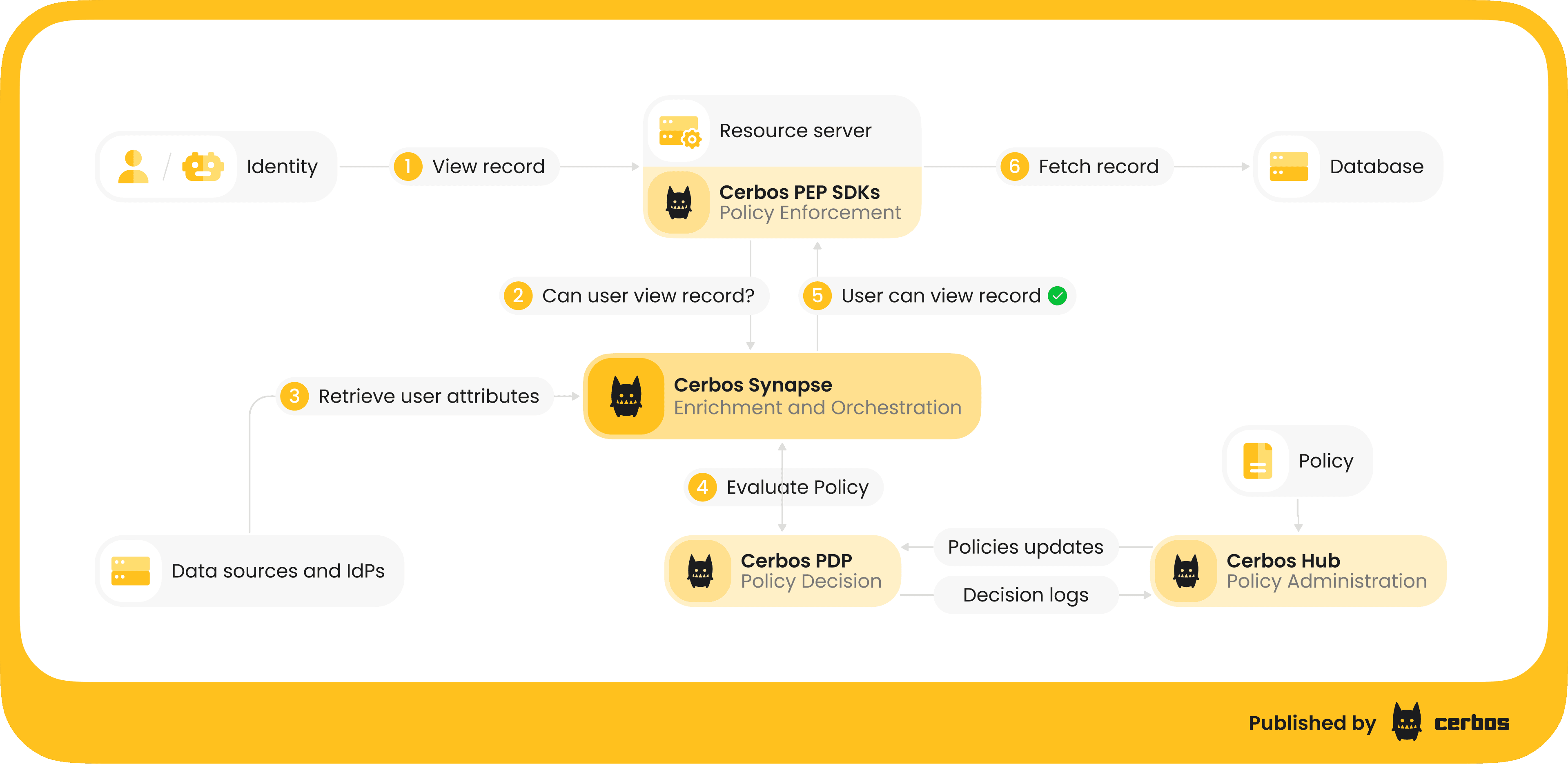
Cerbos Synapse is built on three pluggable components: data sources, proxy extensions, and route extensions.
-
Data sources connect to external systems: identity providers, databases, graph databases, and internal APIs. Built-in connectors cover PostgreSQL, MySQL, and SQLite. Custom connectors can be written in any language that compiles to WebAssembly, so your team is not locked into a single ecosystem. Every data source includes a configurable cache (in-memory or shared Redis) that keeps hot-path enrichment fast (sub-millisecond on a cache hit) and protects upstream systems from per-request query load.
-
Proxy extensions intercept standard Cerbos API calls in transit. On the request path, they enrich principal and resource attributes from configured data sources before the request reaches the PDP. On the response path, they can redact fields, write to compliance logs, trigger workflows, or perform post-decision validation. The calling application sees a standard Cerbos API response and does not know the data layer is there.
-
Route extensions expose new HTTP/gRPC endpoints that accept requests in the format infrastructure systems already use (ext_authz for Envoy, the authorizer interface for Kafka, access control hooks for Trino, admission webhooks for Kubernetes) and translate them into Cerbos calls. The Envoy integration is entirely declarative - no custom adapter binary, no compiled code to maintain. Because both the gateway and the application evaluate the same policies through Synapse, you get layered enforcement without policy drift between perimeter and service.
The same mechanism works for systems that cannot be modified to call Cerbos directly: legacy applications, admin consoles, and internal tooling can be fronted by a route extension without touching their code.
If you want to see Cerbos Synapse in action, join our walkthrough demo. Our engineering team will give you a personalized tour of how it fits into your authorization architecture. You can also explore our documentation for implementation details.
Why this architecture, not the traditional PIP model
The NIST reference architecture defines a Policy Information Point that the PDP queries during evaluation to fetch the attributes it needs. In theory, this is clean. In practice, it creates problems that compound at scale
-
Policy changes become operational risks. A policy author can inadvertently trigger new external calls just by referencing a new attribute. The operational cost of a policy change becomes unpredictable.
-
The PDP inherits upstream reliability. A slow identity provider or an overloaded database doesn't just delay one lookup; it blocks the entire authorization decision. The component that should be fastest becomes only as reliable as the slowest system it queries.
-
Infrastructure decisions hide inside policy. Caching, fallback behavior, and data freshness end up as implicit side effects of policy content rather than explicit choices made by the teams who own the data infrastructure.
Cerbos Synapse addresses all three by separating data resolution from policy evaluation. The Policy Decision Point never makes external calls. Every external system being queried is visible in the data layer configuration rather than hidden inside policy conditions. Caching, fallback behavior, and data freshness are owned by the engineers who manage the data infrastructure, not determined implicitly by policy content.
Authorization beyond the human user
The data integration gap gets worse with AI agents. When a human user calls an API, the application usually knows who they are. AI agents break this assumption.
An agent calling a tool on behalf of a user often includes only an agent ID or a partial reference to the user. It does not have access to the user’s full IdP profile, group memberships, department, or clearance level.
Without enrichment, the policy engine receives incomplete input, leading to either over-permissive decisions or hard-coded workarounds. Either outcome defeats the point of externalized policy. When an agent makes an authorization call, Cerbos Synapse enriches the request across three dimensions:

-
The human behind the agent. A proxy extension takes the delegating user's ID and fetches their full profile from the IdP. The Policy Decision Point receives both the agent's identity and the human's attributes and evaluates both in a single policy call.
-
The resource. A data source lookup retrieves the full resource record from the system that owns it. The agent does not need to know or forward these attributes.
-
The agent's own constraints. Agent ID, tool scope, invocation chain, and runtime environment are injected as principal attributes. Policies can express constraints such as "this agent can only read engineering documents on behalf of users in the engineering department." The same enrichment applies to query planning. An agent can ask what a user is allowed to access, and Synapse returns a fully resolved answer without the agent needing to enumerate permissions.
Every agent request is evaluated against the current policy with fully enriched input data. Cerbos never caches decisions, only input data. A policy change takes effect on the next request, enforcing least privilege across both human and non-human identities.
Getting started
Cerbos Synapse is available for Cerbos Hub customers. The embedded PDP connects to Cerbos Hub for signed policy bundles and decision logs, including the full enriched context stream to your observability platform. Best practice implementation patterns cover identity provider enrichment (Okta, Cognito, Entra ID, LDAP, Keycloak), infrastructure authorization (Envoy, Istio, Kafka, Trino, Kubernetes), protocol translation, and graph-based access control with Neo4j.
For teams already running Cerbos, adoption is incremental. Route traffic through the data layer, configure your data sources and extensions, and start enriching requests without changing application code. The Cerbos API contract remains the same.
Cerbos has always separated policy evaluation logic from application logic. Synapse extends that model by separating data fetching as well, making authorization consistent, observable, and reusable across your entire system.
FAQ
Tagged in





