
Every engineering team I talk to has some version of the same story. They've invested heavily in securing human access. SSO is in place, MFA is enforced, Zero Trust principles govern how people authenticate and what they can reach. Then I ask about their service accounts, API keys, and workload identities, and the conversation gets quieter.
Non-human identities now outnumber human users in most organizations by roughly 17 to 1. A company we work with has 2,500 internal users but over 4,500 services and workloads, each with its own identity, each making requests on behalf of users or other systems. And they had no real visibility into what those services were doing on behalf of their users.
The industry has responded with a growing category of tools and practices called non-human identity management. But most of what falls under that umbrella today addresses only part of the problem. Discovery, inventory, credential rotation, and lifecycle management are all necessary. None of them answer the question that matters most at runtime. When this service makes this request, right now, should it be allowed?
What non-human identities actually are

Non-human identities are the credentials and identities assigned to software rather than people. Service accounts, API tokens, OAuth client credentials, workload identities in Kubernetes, CI/CD pipeline runners, machine certificates, and increasingly AI agents and bots.
They differ from human identities in ways that make them harder to manage. They don't log in interactively. They don't respond to MFA prompts. They're often created programmatically, sometimes by other machines, and they rarely have a clear owner. When a human leaves the company, HR triggers an offboarding flow. When a microservice is decommissioned, its service account often lingers with full permissions indefinitely.
The OWASP Non-Human Identities Top 10 captures the most common risks well. Improper offboarding, overprivileged access, insecure authentication methods, and secret sprawl show up repeatedly in real-world breaches. According to the CyberArk 2025 State of Machine Identity Security Report, 50% of surveyed organizations had a breach in the past year tied to compromised machine identities, with poorly scoped API keys, SSL/TLS certificates, and service account tokens as the most common vectors.
Only 15% of organizations feel confident in their ability to secure NHIs, according to the NHI Management Group. That number should give every engineering leader pause.
What non-human identity management covers today
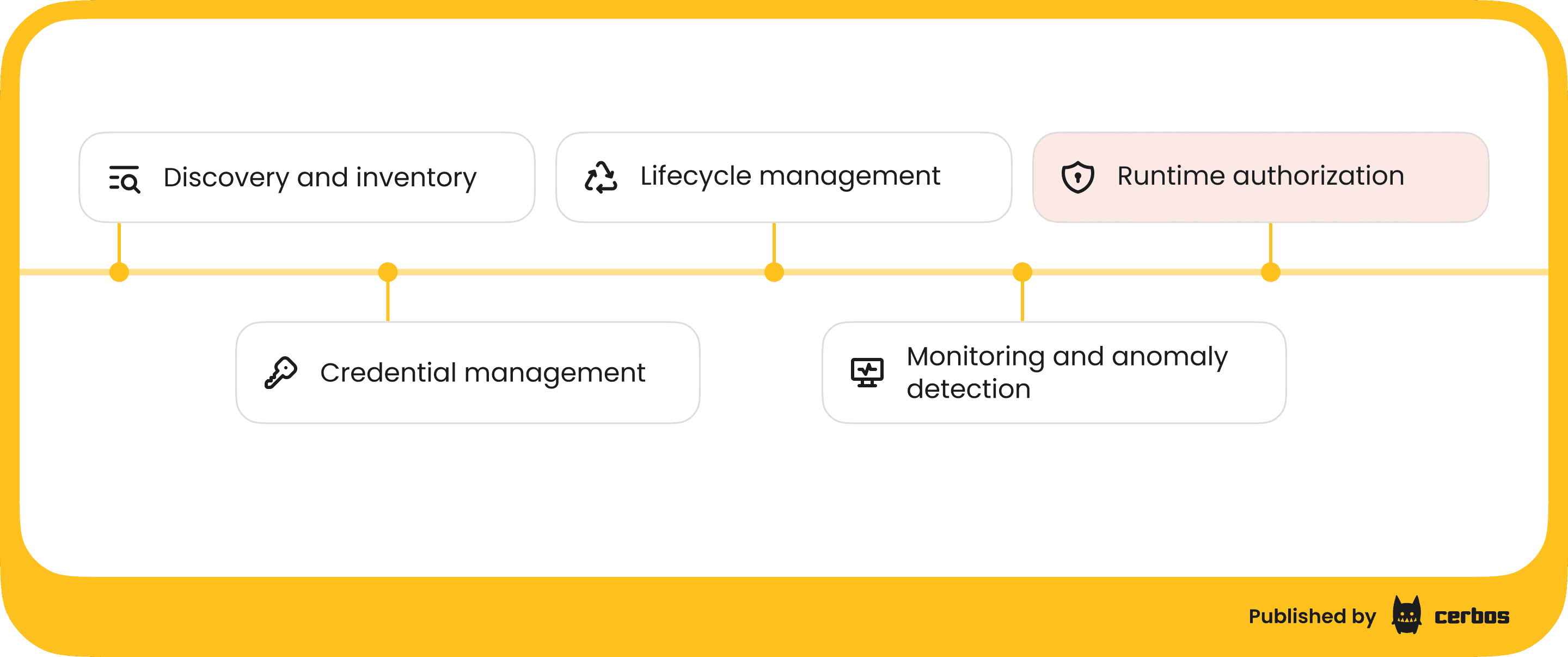
The NHI management discipline has matured significantly over the past few years. Most approaches focus on several core capabilities.
Discovery and inventory is usually the starting point. You need to know what non-human identities exist across your cloud accounts, SaaS integrations, and on-premises systems before you can secure them. Automated scanning surfaces service accounts, API keys, and machine identities that teams may not even know about.
Credential management handles the secrets side. Rotating API keys, replacing static credentials with short-lived tokens, vaulting secrets instead of hardcoding them into application configs. This is critical work. Static, long-lived credentials are one of the most common attack vectors.
Lifecycle management applies governance processes to machine identities. Creating them with clear ownership, reviewing them periodically, decommissioning them when the workload they serve is retired. The goal is to prevent the accumulation of orphaned identities with stale but valid permissions.
Monitoring and anomaly detection tracks how NHIs are actually being used. Baseline normal behavior, flag deviations, alert on suspicious patterns like a service account suddenly accessing resources it's never touched before.
All of this is valuable. But there's a layer missing.
The gap most teams don't see
None of those capabilities answer the runtime authorization question. They tell you that a service account exists, that its credentials are properly rotated, that someone owns it, and that its behavior looks normal. They don't evaluate, on every single request, whether this specific identity should be allowed to perform this specific action on this specific resource given the current context.
This is the authorization layer, and for non-human identities it's almost always handled in one of two ways. Either each service implements its own authorization logic (if statements scattered across application code, often inconsistent across teams), or the organization relies on coarse-grained infrastructure controls like network policies and IAM roles that operate at the wrong level of granularity.
The result is predictable. Services end up overprivileged because it's easier to grant broad access than to define precise policies. A payments service that only needs to read customer payment methods also gets write access to the entire customer database because the IAM role was defined at the service level rather than the action level. An AI agent that should only be able to read certain documents gets blanket access to the entire knowledge base because nobody wrote a policy for the specific actions it performs.
The OWASP NHI Top 10 lists overprivileged access as one of the top risks for good reason. And credential rotation alone won't fix it. You can rotate a key every hour, but if the identity behind that key has more permissions than it needs, a compromised credential still gives an attacker a wide blast radius.
Authorization as the missing piece of non-human identity management
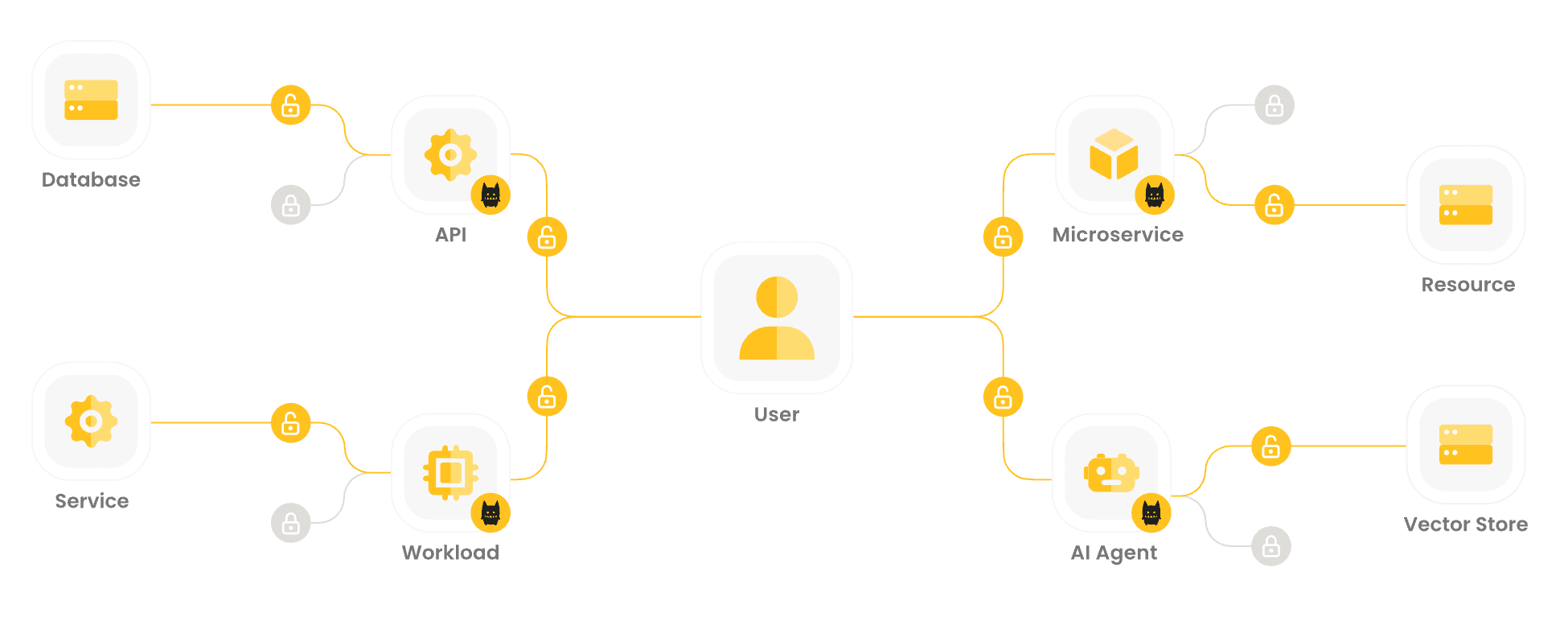
Effective non-human identity management needs runtime authorization that evaluates every request against a defined policy. Not just "does this identity have a valid credential" but "is this identity allowed to perform this action on this resource right now, given everything we know about the request."
This is where Zero Trust principles applied to NHIs go beyond authentication. Zero Trust says never trust, always verify. For human users, that means continuous authentication and contextual access decisions. For non-human identities, it means the same thing, but the identity verification happens through workload identity frameworks like SPIFFE rather than passwords and MFA, and the access decisions need to be just as granular.
A practical NHI authorization layer needs to be centralized so that authorization logic isn't duplicated and potentially inconsistent across services. It needs to support fine-grained policies that can distinguish between different actions on different resources, not just "this service can access this other service." It needs to evaluate context like environment (production vs staging) and the relationship between the requesting identity and the target resource. And it needs to produce audit logs that record every decision, because compliance frameworks like SOC 2, HIPAA, and PCI DSS increasingly require this for all identities, not just human ones.
How this works with Cerbos

Cerbos acts as a dedicated policy decision point that evaluates authorization requests against policies you define. It's stateless, runs as a sidecar or centralized service, and returns decisions in sub-milliseconds, so it fits into whatever architecture your services already use.
For non-human identities, the pattern is straightforward. The calling service authenticates using whatever mechanism is appropriate (SPIFFE, mutual TLS, OAuth client credentials), and your application code or middleware extracts the identity and passes it to Cerbos along with the resource and action being requested. Cerbos evaluates the request against the relevant policy and returns an allow or deny decision.
Here's a policy (source) that controls access to a payment service based on a SPIFFE workload identity, using Cerbos's built-in SPIFFE identity parsing.
apiVersion: api.cerbos.dev/v1
resourcePolicy:
version: v1default
resource: payment_service
rules:
- actions: ["read", "write"]
effect: EFFECT_ALLOW
condition:
match:
all:
of:
- expr: spiffeID(P.id).isMemberOf(spiffeTrustDomain("spiffe://example.org"))
- expr: spiffeMatchExact(spiffeID("spiffe://example.org/ns/privileged/sa/payments")).matchesID(spiffeID(P.id))
This policy does two things. It verifies that the requesting service belongs to the correct SPIFFE trust domain, and it verifies that the service's identity exactly matches the payments service account. Only a service with the right workload identity, from the right trust domain, gets access. Everything else is denied by default.
The authorization request from the calling service looks like this.
{
"principal": {
"id": "spiffe://example.org/ns/default/sa/payments",
"roles": ["internal_service"],
"attributes": {
"service_type": "internal"
}
},
"resources": [
{
"resource": {
"kind": "payment_service",
"id": "invoice-456"
},
"actions": ["read", "write"]
}
]
}
Every authorization check produces an audit log entry, recording the principal, resource, action, and decision. This gives security and compliance teams complete visibility into what every non-human identity is doing and why it was allowed or denied.
Cerbos supports RBAC, ABAC, and policy-based access control simultaneously, so you can start with simple role-based rules for your services and layer in attribute-based conditions as your authorization requirements get more sophisticated.
Getting started
If you're building out non-human identity management for your organization, the authorization layer doesn't need to be the last thing you add. In many ways, it's the most impactful place to start because it addresses the overprivilege problem directly, on every request, from day one.
The approach we see work best is straightforward. Start by identifying your most critical service-to-service interactions. Write policies for those flows, scoped to the specific actions and resources each service actually needs. Deploy Cerbos alongside your existing authentication (whether that's SPIFFE, mutual TLS, or OAuth), and let it handle the authorization decisions. Then expand from there.
For a deeper dive into the implementation specifics, including SPIFFE integration, deployment patterns, and advanced policy examples, see our technical guide to authorization for non-human identities.
We also put together an ebook on securing AI agents and non-human identities in enterprises that covers the broader strategy, and you can watch our on-demand webinar on NHI authorization where we walk through the architecture and live examples.
FAQ
Tagged in





