Artificial Intelligence is transforming business workflows and software architectures, but it’s also introducing new security challenges that traditional tools were never designed to handle. Sensitive data can leak through AI models, malicious prompts can hijack AI behavior, and autonomous “agentic” AI systems might take unpredictable actions.
AI Security Platforms have emerged as a response to these challenges. In fact, Gartner has identified AI Security Platforms as one of the top strategic technology trends for 2026.
In this article, we’ll explain what an AISP is, why it’s crucial for modern software teams, and how it works; with technical depth and practical examples.
What is an AI Security Platform?
An AISP is a unified security solution designed to secure AI workflows end-to-end, covering both the use of third-party AI services and the development of custom AI applications. In simple terms, an AISP acts as a shield and control plane for all AI activities in an organization.
According to Gartner, “AI security platforms (AISPs) consolidate controls to secure both third-party AI services and custom-built AI applications. They address AI-native risks like prompt injection, rogue agent actions and data leakage.” In other words, AI Security Platforms act as a unified shield around AI agents, RAG pipelines, and tool integrations (MCP servers), providing consistent policy enforcement and guardrails across all AI workflows.
Key capabilities of an AISP typically include:
| Capability | Description |
|---|---|
| Centralized AI visibility & governance | Discovering and inventorying all AI models, APIs, and integrations in use, including “shadow AI” usage by employees. This provides a single pane of glass to monitor how AI is being applied across the enterprise. |
| AI usage control and policy enforcement | Enforcing organizational policies on how AI services are consumed. For example, blocking employees from sending sensitive data to unapproved AI chatbots, or restricting which AI tools can be used in certain contexts. This ensures acceptable use of third-party AI and prevents unauthorized access or data exfiltration via AI. |
| Protection against AI-specific threats | Detecting and mitigating AI-native attacks that conventional security misses, such as prompt injection (malicious inputs that trick an AI model into leaking data or misbehaving), jailbreak prompts, or toxic outputs (e.g. an LLM producing disallowed content). AISPs implement guardrails like input sanitization, prompt filtering, and content moderation to neutralize these threats in real time. |
| Secure AI application development | Extending security into the AI model development lifecycle. AISPs scan downloaded models for backdoors or malware, monitor model training for data poisoning, and run automated AI security tests (AI “red teaming”) to probe models for vulnerabilities. They also ensure that custom AI applications have security hooks in place before deployment. |
| Rogue AI agent detection and control | Providing oversight for agentic AI systems; e.g. AI agents that autonomously chain tasks or call tools. AISP solutions can trace an agent’s actions and detect “rogue” behaviors. For example, if an AI agent tries to execute an unauthorized operation or access data beyond its permissions, the platform will flag or block it. This addresses the risk of AI agents that might otherwise perform unintended or harmful actions without human oversight. |
| Fine-grained access control for AI workflows | AISP emphasizes contextual, attribute based authorization for AI. Instead of all-or-nothing access, every AI request or action can be checked against policies that consider who (user or service identity), what (data or tool), and context (sensitivity, risk level) to decide if it’s allowed. This is often implemented via a policy engine that the AI or associated application queries before performing certain operations. |
| Data loss prevention for AI outputs | To maintain privacy and compliance, AISPs can redact or anonymize sensitive information in prompts and responses. They prevent models from returning confidential data, either because it was part of their training set or because a user tried to retrieve it via the AI. For example, if an employee asks a generative AI to summarize internal financial records, an AISP could ensure that only data the employee is permitted to see is included in the response. |
| Continuous monitoring and auditing | Every interaction with AI is logged. AISPs typically log prompts, outputs, decisions taken, and policy checks. This creates an audit trail for all AI activities; crucial for compliance (e.g. proving you have control over AI outputs as required by regulations like the EU AI Act) and for forensic analysis if something goes wrong. Because the platform centralizes these logs, security teams gain much-needed visibility into AI operations that would otherwise be a blind spot. |
In essence, an AI Security Platform is like an AI-focused combination of a firewall, policy engine, and monitoring system. It sits between AI consumers and providers to enforce rules and catch security issues unique to AI.
This unified approach is increasingly necessary because organizations are integrating AI into critical workflows, and traditional security architectures focused on endpoints, network, or cloud, can’t inspect or control the internal behavior of AI models (e.g. what an LLM was asked and how it responded). AISPs fill that gap by operating at the AI layer - looking at prompts, model responses, and AI agent actions - to apply security and governance.
Why AI Security Platforms matter now
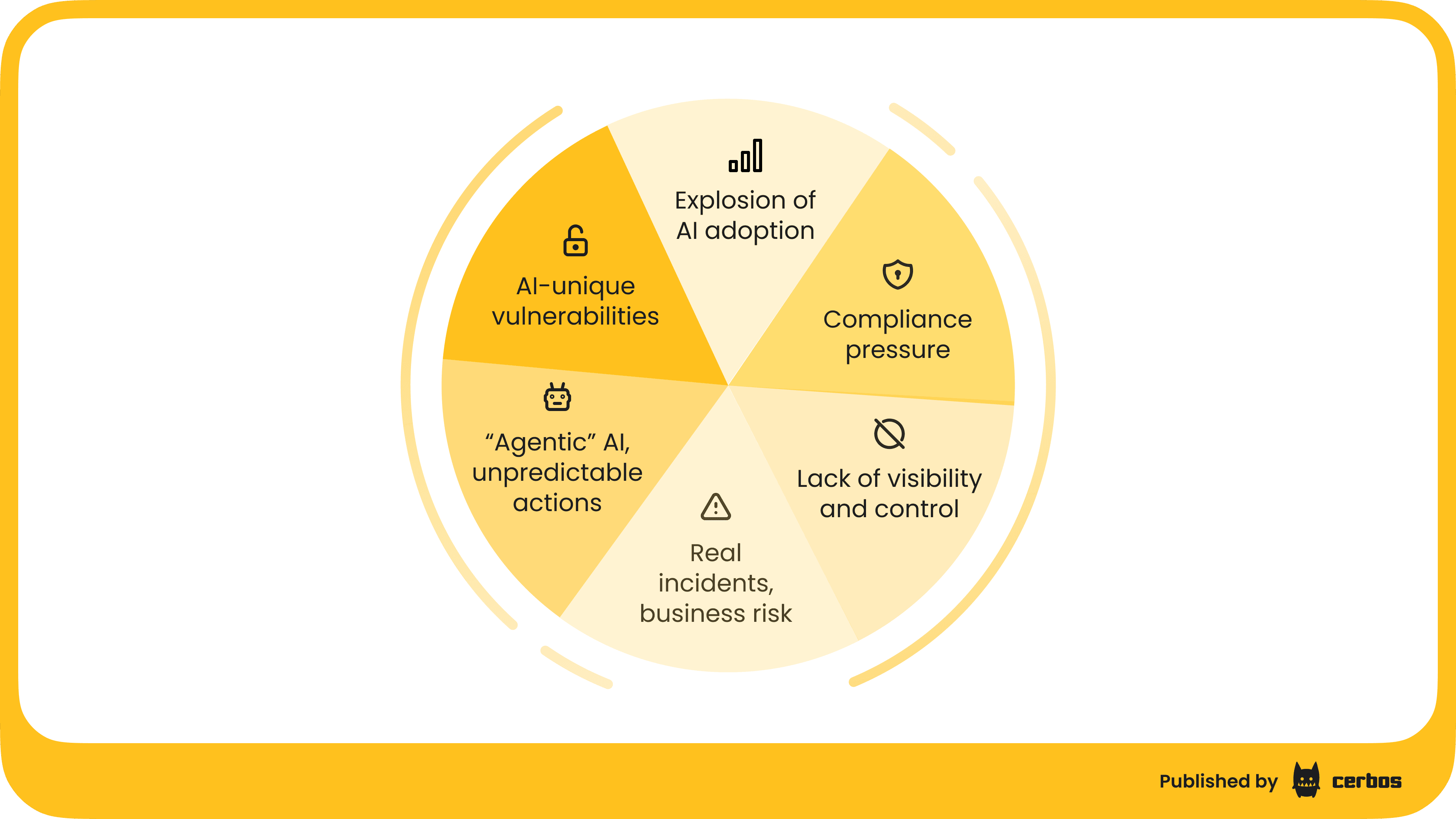
Several converging factors have made AISPs a priority for forward-looking teams.
Explosion of AI adoption. Organizations are rapidly embedding generative AI and “agentic AI” into everything from customer service bots to decision support tools. Every new AI integration, whether it’s calling an OpenAI API or deploying a custom model, introduces potential vulnerabilities if left unprotected.
New vulnerabilities and AI-unique attacks. With AI usage has come a wave of new exploits. For example, prompt injection attacks, that we mentioned before, involve feeding a model carefully crafted input that causes it to ignore its instructions or reveal confidential data. Similarly, an attacker might trick an AI assistant into outputting system file contents or API keys by cleverly phrasing a request. These are not hypothetical. Such attacks have been demonstrated against real LLMs, which often can’t distinguish between a legitimate user query and a maliciously formatted prompt. Traditional security tools, like web application firewalls or DLP systems, have no understanding of these AI-specific threats. An AISP is built to detect and defuse these, e.g. by scanning prompts for known injection patterns or restricting the model’s response if it attempts to reveal sensitive info.
“Agentic” AI and unpredictable actions. Unlike traditional software, many AI systems, especially autonomous agents or multi-agent systems, don’t follow a fixed, deterministic script. An AI agent given an open-ended goal might chain together APIs, database queries, and external tool calls to achieve it, sometimes in creative or unintended ways. This introduces agentic risk: the AI may do something outside the bounds of what a user or developer expected. For example, an AI marketing assistant might decide to scrape a customer database it shouldn’t have access to, or an automated DevOps agent might attempt to shut down servers thinking it’s resolving an incident. Since these agents operate probabilistically, their behavior is less predictable and can bypass normal approval workflows. Gartner warns that custom AI agents create “new attack surfaces and uncertainty”, requiring strict development-time and runtime security practices. AISPs address this by controlling AI agent actions in real time; every tool invocation or high-impact action can be authorized against policy, and anything outside of policy is blocked or flagged. Essentially, the AISP puts a leash on autonomous AI to keep it operating within safe boundaries.
Lack of visibility and control with conventional tools. Most organizations currently have limited to no visibility into what prompts users are entering into AI systems, what outputs they are getting, or what data is flowing through these models. For instance, a data scientist might be using a SaaS AI service and feeding it proprietary data, but the security team would never know because it all happens client-side or over an API that isn’t being monitored by traditional network security. There is no native way to block an AI prompt or audit a model’s output with existing security controls. This invisibility is risky: you can’t protect what you can’t see. AISPs introduce an AI-aware control layer that sits in the path of AI interactions, often called an AI Gateway when implemented as a proxy - more on this below. This means all AI queries and responses can be inspected, filtered, or logged. Suddenly, things like “Which corporate data was sent to external AI services this month?” or “Has our custom LLM ever generated disallowed content?” become answerable questions.
Compliance and regulatory pressure. With AI usage comes regulatory scrutiny. Laws like the EU AI Act, various data protection regulations, and sector-specific guidelines are mandating that organizations govern their AI systems, manage risks, and maintain auditability. For example, the EU AI Act will require transparency around AI decision-making and proof of risk controls for high-risk AI applications. Internal policies, like “no using customer data in public AI without approval”, are also on the rise. Without a dedicated AI security mechanism, these rules are practically unenforceable; you rely purely on trust or after-the-fact manual reviews. AISPs enable preventive compliance: they can enforce “AI cannot do X” policies in real time and log evidence of every decision, which makes passing audits and meeting regulatory requirements much easier. Essentially, an AISP bakes governance into the AI pipeline from the start.
Real Incidents and business risks. Companies have already experienced breaches or mishaps attributable to AI misuse. For instance, consider a scenario where an employee uses an AI coding assistant and inadvertently shares API keys or internal source code, which then gets exposed. Or a case where an AI system hallucinated a customer’s personal info from training data, causing a privacy violation. These kinds of incidents are increasingly reported. Gartner notes that many early AI projects have run into failures or compliance issues due to inadequate oversight. The cost of such incidents, from data breaches to reputational damage, is pushing security leaders to proactively invest in AI-focused defenses.
In summary, AI Security Platforms matter now because AI is no longer a niche experiment sitting on the sidelines - it’s moving into the core of business operations. With that shift, entirely new classes of risks have emerged, and ignoring them is not an option. Traditional cybersecurity tools are blind to the inner workings of AI models and the nuances of AI-driven workflows.
AISPs fill that void, providing the trust, safety, and control layer needed to confidently deploy AI at scale. Organizations that treat AI security as just an extension of existing security will likely be left behind by those that adopt a platform-native approach to AI risk management.
Core pillars and capabilities of AI Security Platforms
While specific products and solutions vary, most AI Security Platforms share a common set of capabilities. These can be thought of as two broad pillars, as described by Gartner’s framework.
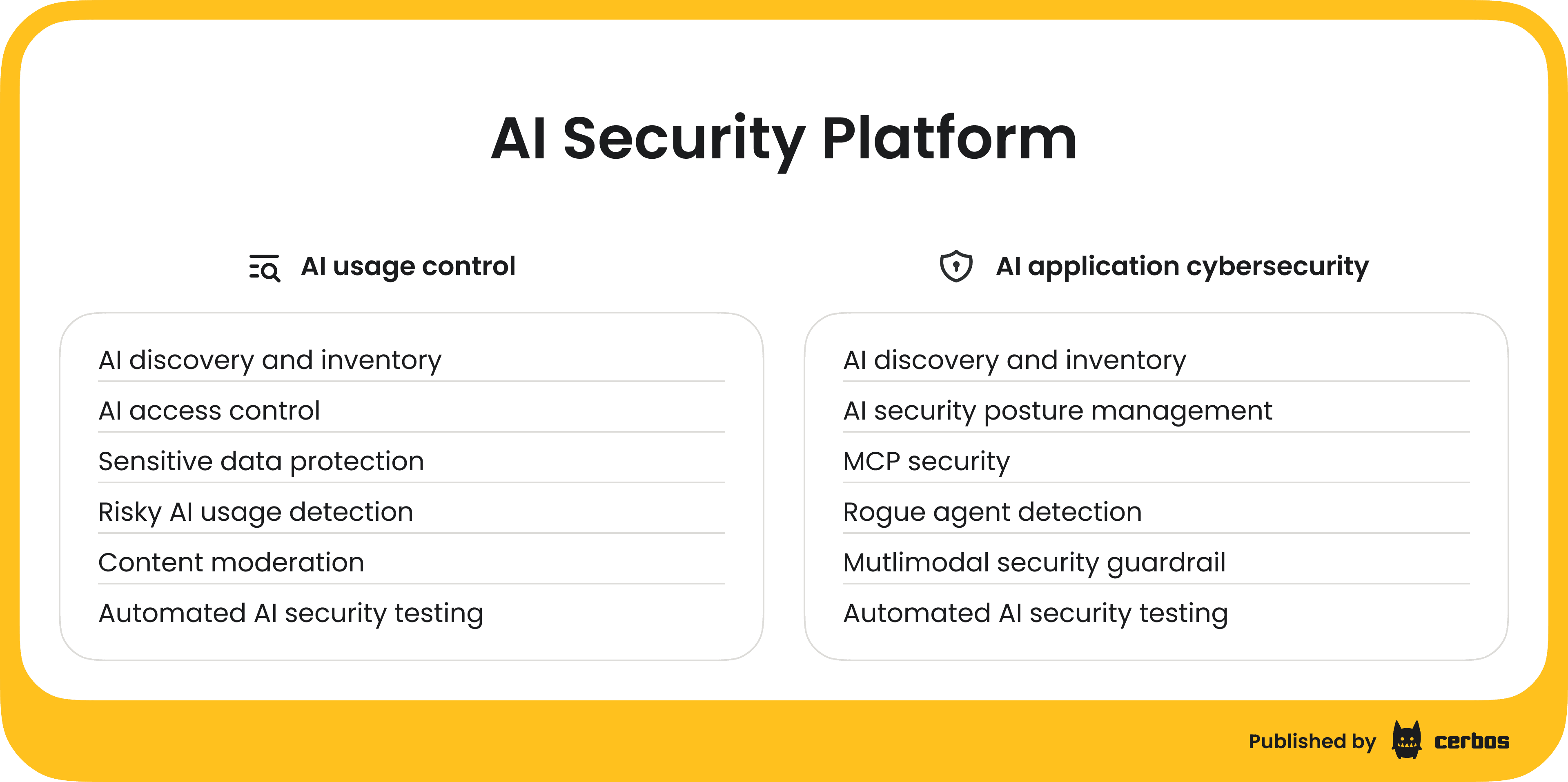
1. AI Usage Control (AIUC)
AI Usage Control focuses on governing how users, or even other systems, interact with third-party AI services; for example, public generative AI APIs and SaaS offerings like ChatGPT, Bard, DALL·E, etc., as well as any external AI tools employees might adopt. The goal of AIUC is to enforce acceptable use policies and prevent data misuse when leveraging third-party AI. Key capabilities include:
Discovery & inventory of AI services. Automatically identifying what external AI services are being used in the organization. This tackles the “shadow AI” problem, e.g. detecting if employees are plugging company data into some online AI writer or if teams have spun up cloud AI instances outside official processes. An AISP might integrate with network proxies, browser plugins, or cloud logs to map out all AI usage.
Policy enforcement for external AI. Applying granular policies on AI service usage. For example, an organization might allow using ChatGPT, but only the enterprise-approved version and only with de-identified data. Or they might block use of any AI service that isn’t vetted. AIUC can implement these rules: blocking requests to disallowed endpoints, injecting legal disclaimers or watermarking outputs, or forcing certain prompts through an approval workflow. It ensures AI use aligns with corporate policies and industry regulations.
Data protection and filtering. Preventing sensitive information from leaking via prompts or responses. The AISP can scan prompts for things like PII, secrets, or client data, and mask or redact it before the prompt is sent to an external AI. Similarly, it can inspect AI outputs for sensitive content or policy violations (hate speech, personal data, etc.) and filter or modify them. This is essentially Data Loss Prevention for AI, operating on both input and output.
Content moderation & output safety. Ensuring that AI-generated content doesn’t violate compliance or safety guidelines. For external AI services that might return uncensored outputs, the AISP can add a layer of moderation; e.g. stripping out profanity or disallowed info, and implementing guardrails to catch hallucinated facts that could be harmful. This capability builds user trust in AI results by keeping them within safe bounds.
Monitoring & risk analytics. Continuously monitoring usage patterns for signs of risky behavior. For example, if an employee suddenly starts pasting large chunks of database records into an AI chatbot, that’s unusual and risky - the platform can flag it. AIUC provides dashboards and alerts for the security team, highlighting trends like “Top 10 users of external AI this month” or “Potential policy violations by AI prompts.” Over time, this helps quantify AI usage and risk in the organization.
Automated AI vulnerability testing. Some AISPs include the ability to test third-party models from the outside, essentially sending various crafted prompts to see if the model can be induced to do something it shouldn’t. Like a penetration test for AI. While many third-party AI APIs are black boxes, an enterprise can still use this technique on any accessible model to understand its failure modes. The findings, e.g. “Model X can be tricked into revealing other users’ data with prompt Y”, help refine the usage policies.
It’s worth noting that AI Usage Control often complements existing security tech like Secure Web Gateways or Cloud Access Security Brokers. In fact, while some traditional Security Service Edge vendors are starting to incorporate AI traffic inspection, a dedicated AIUC layer brings AI-specific context and controls that general web proxies lack. For example, an SSE might block access to a known malicious URL, but it won’t know how to parse an AI prompt or result. AIUC fills that gap with policy-driven, AI-aware filtering.
2. AI Application Cybersecurity (AIAC)
The second pillar, AI Application Cybersecurity, is about securing the organization’s own AI systems and solutions, including custom AI models, internally developed AI applications, and AI agents running within the enterprise environment. If AIUC is analogous to governing third-party SaaS usage, AIAC is analogous to classic AppSec but for AI. It deals with the unique security challenges in building and deploying AI. Key capabilities include:
Model and supply chain security. Scanning and vetting AI models and datasets before and during deployment. For instance, if developers download an open source LLM or incorporate a third-party model checkpoint, the AISP can scan it for known malicious payloads or backdoors. This is similar to container or library scanning in traditional apps. Additionally, AISPs maintain an inventory of all models in use, tracking their versions, source, and lineage. This way, if a particular model is later found to have a vulnerability, say, it always leaks a portion of its training data, the organization knows exactly which apps are affected. Model provenance and integrity checks, like verifying checksums, using signed models, are also part of this.
Secure model development lifecycle. Integrating security testing into AI model training and fine-tuning. Before a new model goes live, an AISP can conduct automated red-team attacks on it - for example, trying a library of exploit prompts to see if the model can be prompted to break its guardrails or produce biased output. The results can be used to harden the model - adjust training, add prompt filters, etc. AISPs can also enforce that no sensitive training data is used without proper anonymization, preventing issues like models memorizing personal data.
Runtime guardrails for custom AI apps. Deploying guardrail policies within AI applications at run-time. For example, if you have an internal chatbot that integrates with your databases, the AISP can ensure that each query the bot makes to a database is authorized for the requesting user. If the AI tries to retrieve data the user shouldn’t see, the AISP will block that query. This might involve hooking into the AI app’s code or using an AI gateway/proxy that the app communicates through. Another guardrail example is multimodal security - if an AI app accepts images and text, the AISP may scan uploaded images for steganographic attacks or malicious content, not just scan text prompts. Guardrails also include things like restricting the format of AI outputs to prevent injection attacks in, say, code suggestions or HTML outputs.
Agent behavior monitoring and intervention. Many organizations are experimenting with AI agents that can act autonomously. For example, an AI Ops agent that can open tickets or restart servers. AIAC capabilities include agent monitoring - logging every action the agent takes (API calls, file writes, tool invocations), and agent policy enforcement - applying rules to those actions. For instance, a policy might state an AI agent is allowed to read from an internal knowledge base but never allowed to delete or modify data. If the agent attempts the latter, the AISP will intervene, and likely disable the offending agent tool. Essentially, the AISP treats AI agents as just another type of “user” whose privileges are tightly controlled.
Incident response for AI. AIAC also covers having the mechanisms to respond when something goes wrong. If a custom AI app starts generating harmful outputs or an agent starts behaving erratically, the AISP can provide a kill switch or quarantine function. E.g. halting the model’s responses, locking its API keys, or sandboxing the agent. Since all actions are logged, the security team can perform root cause analysis: was it a malicious input, a software bug, or a compromised model? These are new kinds of incidents that security teams are learning to handle, and AISPs give them the observability and control to do so.
AIAC capabilities deliver end-to-end protection across the AI development lifecycle. Something no conventional AppSec or supply-chain tool can achieve. Traditional AppSec might check your web app for SQL injection, but it doesn’t know how to check your AI’s knowledge base for prompt injection vulnerability, for example. Similarly, software composition analysis tools track open source libraries, but an AISP tracks your models and AI datasets with the same rigor. In effect, AIAC is building a new layer of security practice parallel to DevSecOps, often dubbed “LLMSecOps” by practitioners.
How AI Security Platforms work in practice
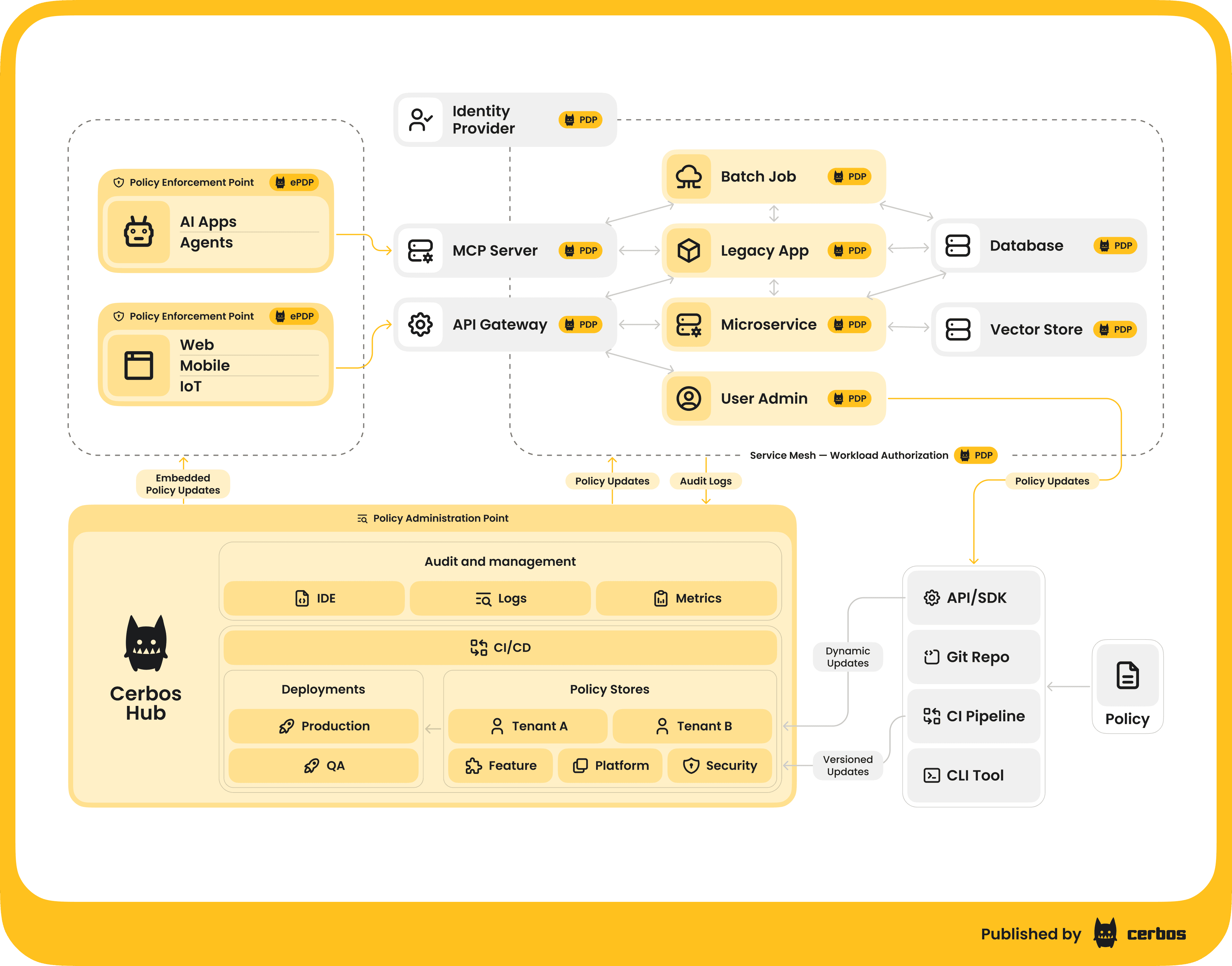
So how are these AI Security Platform capabilities actually implemented? The architecture of an AISP typically involves a combination of policy enforcement points and a central brain that manages policies, decisions, and analytics. Let’s break down a common deployment model.
AI gateway / proxy
Many AISPs introduce an intermediary layer, often called an AI Gateway, that sits between AI consumers - apps and users, and AI providers - external services or internal models. All AI requests and responses flow through this gateway. This is analogous to an API gateway or firewall, but specialized for AI traffic. The gateway can be deployed as a cloud service, a sidecar, or a middleware component.
Its job is to intercept each prompt or action and apply the security and policy checks. For example, when a user’s application calls the LLM’s API via the gateway, the gateway will first inspect the request: Are we sending sensitive data out? Is this user allowed to call this model? It might call the central policy engine (described next) to get a decision. Only if everything checks out does it forward the request to the actual AI model or external API.
Similarly, on the response path, it will inspect the model’s output: Does it contain disallowed content or any data it shouldn’t reveal? It can modify or block the output accordingly.
The AI gateway is effectively the enforcement point for runtime controls. It’s also where you implement things like routing logic - ensuring requests with certain data go to an on-prem model for compliance, while others can use a cloud model - enforcing data residency rules. And load balancing across models. By funneling all AI interactions through a gateway, you gain a powerful control point.
Policy Decision Point
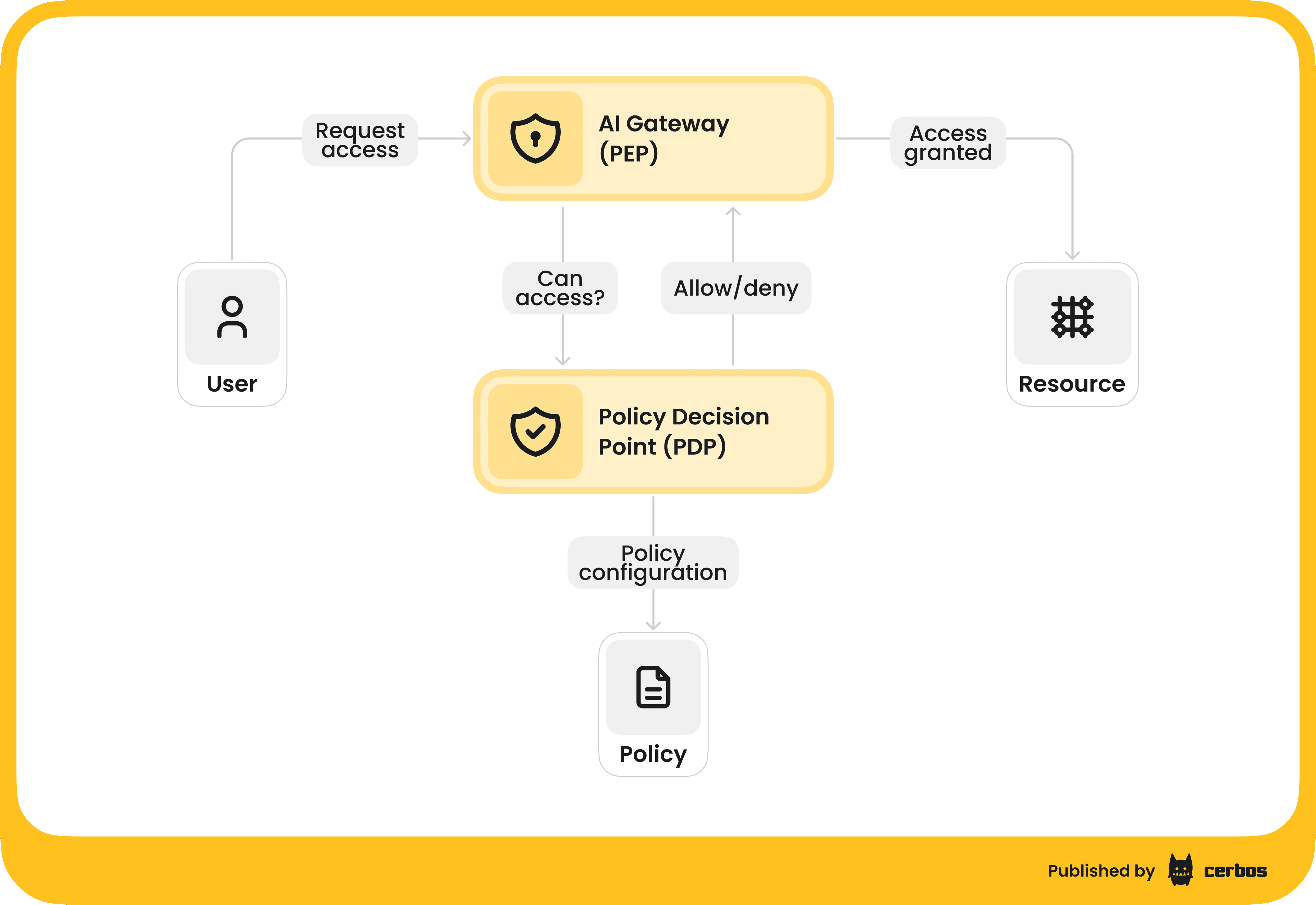
Under the hood, AISPs usually have a policy engine that makes the allow/deny decisions. This engine takes as input the context of an AI action: who is doing it, what the action is (e.g. calling a tool, reading a dataset, generating text), and any relevant attributes, such as data sensitivity, time of day, etc. It then evaluates this against predefined policies, often written in a declarative language, and returns a decision (allow, deny, redact, etc.) along with possibly some meta-information, like which policy rule was triggered.
The AI gateway will use this decision to permit or block the action. For performance, these PDP checks need to be very fast - think milliseconds, and they are often stateless and scalable. Modern AISPs might integrate with existing identity systems for context, hooking into your IAM to get user roles, and with data catalogs, to understand data sensitivity. Essentially, the policy engine brings in all the contextual intelligence and makes a judgment call each time an AI request happens. It’s a continuous, automated enforcement of your AI security policies.
Integration with AI platforms and dev workflows
On the internal AI application side, an AISP might integrate as a library or SDK within your AI application code. For example, if you have a Python app that uses an ML model, you might add hooks to call the AISP’s policy API before executing certain functions. Alternatively, containerized AI services might run in a protected environment where the AISP agent monitors their system calls or API calls, similar to how an Application Security Runtime monitoring works. During development, plugins for Jupyter notebooks or ML pipelines might flag insecure practices, like using a sensitive dataset in training without approval. These integrations ensure that security is not just slapped on at the end, but is present throughout the AI lifecycle - from model development to deployment to runtime usage.
Continuous feedback and learning
AISP solutions often leverage AI themselves to improve security over time. The logs of prompts and attacks can feed into machine-learning models that help detect anomalies or predict which prompts might be malicious. For example, an AISP could train a classifier on past prompt injection attempts to recognize novel ones in the future, beyond simple regex rules. Some platforms might offer risk scoring - analyzing an AI’s outputs or an agent’s behavior and assigning a risk level, which can then trigger stricter oversight if the risk is high - risk-based usage control. In a mature implementation, the AISP becomes an intelligent assistant to the security team, highlighting the most significant events out of potentially millions of AI interactions.
From an engineer’s perspective, adopting an AISP means you will have an additional layer in your architecture. Applications might need to route their AI calls through the gateway or use the AISP’s SDK. This is analogous to how many apps today use a central identity service - now it’s a central AI AuthZ/monitoring service. The benefits, however, far outweigh the slight complexity: you get centralized management of AI security, easier compliance, and the ability to actually use AI in production with confidence.
Cerbos supporting an AI Security Platform
Now that we’ve covered the concept and components of AI Security Platforms, let’s look at how these ideas can be put into practice using Cerbos - an authorization solution for enterprise software and AI.
Cerbos is not a full all-in-one AISP by itself, as it focuses on the authorization and policy enforcement aspects, but it serves as a powerful building block to implement many AISP capabilities. In fact, Cerbos can be thought of as the policy decision engine and authorization layer within an AI Security Platform. Its strength lies in defining fine-grained, context-aware access rules and evaluating those rules in microseconds for each request or action.
Cerbos provides fine-grained, contextual, and continuous authorization - exactly the kind of control needed for AI usage and AI agents. By integrating Cerbos into your AI workflows, you can achieve several of the AISP goals we discussed.
Achieving AISP goals with Cerbos
Secure agentic workflows. When you have AI agents performing tasks on behalf of users, Cerbos can ensure those agents only do what they’re permitted to. For example, if an AI agent is connected to a suite of enterprise tools via a Model Context Protocol server, Cerbos policies can determine which tools, and which specific actions, that agent is allowed to invoke for a given user session. The AI agent effectively inherits a restricted permission set. Cerbos treats the agent’s requests just like a user’s requests, checking them against policies that encode business and security rules. This prevents rogue agent behavior like an agent making an unauthorized change in a system or exfiltrating data. The identity of the agent, and the user it represents, the tool being called, and the context all feed into the decision. This aligns with the concept of agentic identity security - giving AI agents an identity and enforcing least privilege on them, just as you would for a human user.
Secure RAG pipelines. In retrieval-augmented generation, the LLM’s answers are only as safe as the data you allow it to see. Cerbos can act as a gatekeeper for data retrieval. Before the retrieval component pulls documents or vectors for the LLM, it can query Cerbos: “What conditions allow user Y to access documents?” with context attributes like document classification, user role, purpose, etc. Cerbos will return a contextual, dynamic set of conditions based on policies to be added to the retrieval step of an RAG pipeline, to ensure only the documents the user has permissions to can be retrieved. This ensures the AI system only retrieves information the user is authorized to see, preventing inadvertent leakage of confidential data via the AI. For instance, if a customer support bot is using a vector database of knowledge, Cerbos policies could ensure a support rep’s query doesn’t retrieve engineering documents that are off-limits to support staff. The result is fine-grained authorization inside the AI’s retrieval step, plugging a major hole that could lead to privacy violations.
Secure MCP servers and tool integrations. Model Context Protocol servers allow AI agents to call external functions/tools. Without proper controls, an MCP server might expose dangerous functionality to an AI agent. Cerbos can be embedded into the MCP server to manage permissions for each tool on a per-user, or per-agent, basis. When an agent connects, the MCP server asks Cerbos which tools to enable for that session. For example, you could have policies that say analyst agents can run read-only queries, but admin agents can perform write operations - or that a certain high-risk tool is only available if the agent’s risk score is low and a human approved it. Cerbos enforces these rules dynamically: unauthorized tools are simply invisible to the agent. In practice, this means even if the AI model wants to use a certain tool, it won’t be able to unless the policy allows, effectively sandboxing the agent. This greatly shrinks the blast radius of what an AI agent can do, making agentic AI far more controllable and auditable.
Fine-grained, contextual decisions - PBAC/ABAC. Cerbos uses a policy language that supports attribute-based conditions, enabling truly fine-grained control. You’re not limited to simple role checks. Policies can consider attributes of the user (role, department, clearance), the resource (data sensitivity, record owner, etc.), and the action context (time, location, risk level). This is powerful for AI scenarios. For example, you might allow an AI agent to approve an expense only if the amount is below a certain limit and the agent’s user has a manager role. If above that amount, the policy could deny or require escalation. This contextual enforcement is continuous - every request is evaluated against the latest policy, so changes take effect immediately and there’s no caching risky decisions.
Policy-driven access control and unified logging. With Cerbos, authorization policies are code, written in YAML or JSON, which means they are versioned, testable, and reviewable. This is crucial for AI security because you might refine policies often as you learn about new risks. You can maintain policies for AI usage alongside your regular access policies. Cerbos also provides detailed decision logs. Each decision can be logged with the policy rule that was applied, the input context, and the outcome. These logs can feed into a SIEM or monitoring dashboard. In the AI context, that means every prompt an AI agent made to a tool could be logged along with whether it was allowed or denied and why. This level of audit trail is gold for both compliance and debugging. If an incident occurs, you can trace exactly what the AI tried to do and which rule failed to stop it (if any). Moreover, because Cerbos externalizes the authorization logic, developers don’t hard-code security into the AI applications. This decoupling makes it easier to update policies without modifying code, essential in the fast-evolving landscape of AI threats.
Policy example
To make this concrete, let’s look at a policy example using Cerbos. Suppose we have an AI agent that manages expense reports via an MCP server, as in a scenario from earlier. We want to ensure: regular users can list and add expenses; managers can also approve or reject expenses, but only their team’s, perhaps; and only admins can delete expenses or use a special “superpower” tool. We can express these rules in a Cerbos policy file:
apiVersion: "api.cerbos.dev/v1"
resourcePolicy:
version: "default"
resource: "mcp::expenses"
rules:
- actions: ["list_expenses"]
effect: EFFECT_ALLOW
roles: ["admin", "manager", "user"] # Everyone can list
- actions: ["add_expense"]
effect: EFFECT_ALLOW
roles: ["admin", "manager", "user"] # Everyone can add (or could restrict to just "user")
- actions: ["approve_expense", "reject_expense"]
effect: EFFECT_ALLOW
roles: ["manager", "admin"] # Only managers (and admins) can approve/reject
- actions: ["delete_expense", "superpower_tool"]
effect: EFFECT_ALLOW
roles: ["admin"] # Only admins can delete or use special tool
This human-readable policy can be stored in Git and reviewed by both developers and security teams. When the MCP server uses Cerbos, it will query this policy for each agent’s requested action. If, say, a user role tries to approve an expense, Cerbos will return a deny, because the role doesn’t match - the MCP server will not enable that action for the AI agent. All of this happens at runtime in milliseconds.
Now, extending this with ABAC, if we wanted managers to only approve expenses under a certain amount, we could add a condition in the policy, using attributes like request.resource.attr.amount, to allow only if amount < $1000. The AI agent or tool would provide the amount attribute when asking Cerbos, and Cerbos would enforce that business rule on the fly.
Cerbos architecture in the AI stack
Typically, you would run the Cerbos Policy Decision Point as a service - it’s stateless and can be containerized. Your AI gateway or your AI application calls Cerbos’s API whenever an authorization check is needed. Cerbos Hub can be used to manage and version the policies centrally, so updates are distributed to PDP instances. This essentially plugs Cerbos into the AISP architecture as the brains behind the authorization decisions (the PDP in our earlier description). Because it’s built for performance and scale, it can handle the high frequency of AI calls. Also, Cerbos is language-agnostic and works via API/SDKs, so it can be integrated whether your AI components are in Node.js, Python, Java, etc., or at the API gateway level.
| Example integration |
|---|
A Node.js MCP server uses the Cerbos gRPC client to check a list of tools against policy for a given user session. Pseudocode: authorizedTools = cerbos.checkResource({principal: user, resource: "mcp::expenses", actions: toolNames}). |
| The server then enables only those tools that came back allowed. In a web app scenario, an AI microservice could similarly ask Cerbos “What conditions need to be met for User X to access specific documents in the vector store?” before retrieving documents for RAG. |
| In both cases, Cerbos decouples the rules from code - you can adjust who can do what by editing the policy, without touching the application logic. |
Zero Trust enabled by Cerbos
Cerbos’s approach aligns with Zero Trust principles, which are highly relevant for AI security. Zero Trust says “authenticate and authorize every action, and assume no inherent trust.” In the AI world, this means even if an AI component is inside your network, you don’t implicitly trust it with broad access - you explicitly check every operation. Cerbos enables this continuous verification for AI agents and services, enforcing least privilege at each step. Every API call an AI makes can carry its identity, or the user’s identity it’s acting for, and Cerbos will validate it against policy before the call goes through. This prevents scenarios where an AI could be used as a pivot point for lateral movement or privilege escalation (e.g. an AI with a leaked credential trying to access more than it should - Cerbos would stop those extra accesses because they violate policy).
Lastly, decision logging in Cerbos helps greatly with auditing AI actions. Cerbos can log each decision with structured details - who the actor was, human or AI service, what action was taken, on what resource, and whether it was allowed or denied. In the context of AI, you feed these logs to your SIEM or monitoring stack. This means your security operations team can query “show me all denied AI agent actions in the last 24 hours” or “which AI requests were blocked due to sensitive data policy”. It closes the observability gap. You can even replay decisions if needed: Cerbos can simulate decisions using historical policy versions, aiding in incident investigations to see “what would the latest policy do?”.
By incorporating Cerbos into your AI ecosystem, you essentially implement the authorization and governance backbone of an AI Security Platform. Cerbos provides the fine-grained control plane to secure AI agents, LLM gateways, and data pipelines in a consistent way. It lets you launch AI features faster because you don’t have to hand-code a bunch of security checks; instead, you declare policies and rely on the platform to enforce them. And as your AI use cases evolve, you can adapt the policies without refactoring application code - making your AI adoption not just secure, but also agile.
Conclusion & next steps
AI Security Platforms are becoming indispensable as organizations embrace AI. An AISP gives you the peace of mind that you can innovate with AI while maintaining control, compliance, and safety. It provides the technical guardrails (prompt injection defense, usage oversight, access control, testing, and more) that ensure AI systems behave in alignment with business and security requirements. Implementing an AISP means adding critical components to your architecture - such as AI gateways and policy engines - and weaving security into the fabric of your AI workflows from day one.
Cerbos plays a key role in this landscape by offering a robust, developer-friendly way to implement many AISP capabilities around authorization and policy enforcement. With Cerbos, you can secure AI agents, RAG pipelines, MCP servers, and AI-powered applications with fine-grained, context-aware rules and have full visibility into decisions. It’s a tangible step toward building an AI Security Platform tailored to your needs.
Ready to enhance the security of your AI initiatives? To see Cerbos in action as part of an AI Security Platform, explore Cerbos’ AI security use case and get started here: AI Agent Security With Granular Authorization, or book a call with a Cerbos engineer. By leveraging Cerbos and the principles discussed above, you can confidently deploy AI systems that are not just intelligent and innovative, but also secure, compliant, and trustworthy.
FAQ
Tagged in





