
At ISC2 Security Congress 2025 in Nashville, I had the chance to join a panel alongside Vatsal Gupta (Senior Architect at Apple) and Nandini Singh (Staff TPM at Google) to talk about something most security leaders are wrestling with right now - how to move identity and access management beyond the approval queue and toward something that actually works at scale.
The session was called "Beyond Approvals - Automating IAM for Compliance, Security, and Business Agility." If you were there, great to see you. If not, here's the full rundown.
The state of IAM is painful, and everyone knows it

Nandini kicked things off with a reality check on where IAM sits today. Identity has become the cornerstone of cybersecurity, and McKinsey pegs 80% of organizations as having moved to an identity-first security model. But moving to identity-first doesn't mean the problems are solved. It means a whole new set of growing pains have arrived.
The challenges she laid out will feel familiar to anyone running a security program. Approval fatigue is rampant - you're getting tonnes of access requests from people across the organization for resources you barely understand, and you approve them because you don't have the bandwidth to investigate each one. Privilege creep remains one of the biggest risk vectors, with old permissions left in place long after someone has moved on from the project or role that justified them. Complex IAM processes and constant MFA prompts are driving people toward insecure workarounds. And governance is fragmented across multiple teams, tools, and unaudited SaaS platforms that make unified policy enforcement incredibly difficult.
None of this is news if you're a CISO. But framing these as the starting point matters because it sets up the real question - what do we actually do about it?
Two approaches to moving past the approval queue
The panel explored two complementary strategies for getting IAM out of the approval-driven, rubber-stamping rut it's stuck in. Just-in-time access (JIT) and policy-based access control (PBAC).
Just-in-time access - removing standing privileges
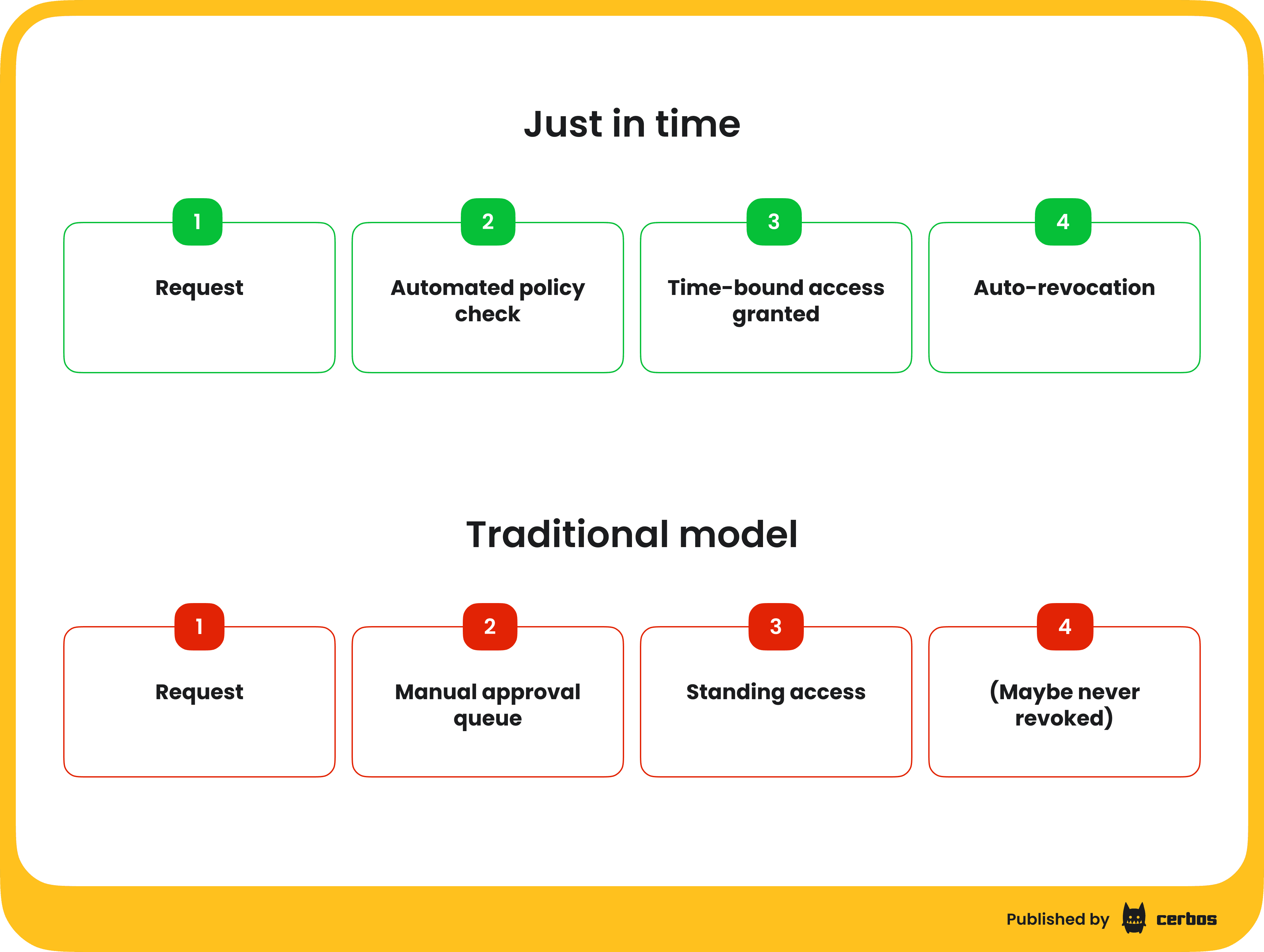
Vatsal's framing of JIT was sharp. The core problem is standing access - continuous access to critical resources for extended periods that creates a permanent target for attackers. All they need to do is compromise one of those accounts and they're in.
The important distinction he made is that JIT should be about removing humans from the approval loop, not just speeding up the loop. Instead of waiting for a manager to click approve, you define policies in advance. If a person is on SRE, if they're on call, if they meet certain criteria, then they get the access they need automatically, for the duration they need it, and it gets revoked when the window closes.
He broke JIT into three flavours:
- Justification-based access is checking out existing admin accounts from a vault for a specific task.
- Ephemeral accounts are short-lived accounts created for a specific purpose, ideal for third parties or break-glass scenarios.
- Temporary elevation is the classic JIT pattern - a user with base access gets a time-bound boost to complete a specific task.
The benefits stack up quickly when you compare this to traditional access models. Standing privileges become time-bound minimal exposure. Paper compliance becomes real compliance with a strong audit trail of when access was granted, why, and for how long. Users stop waiting days or weeks for an approver in a different time zone. And access reviews stop being a months-long project of rubber-stamping because access is aligned to actual need by design.
But JIT has real limitations. If you don't have a predefined approval policy for a particular scenario, such as a cross-department project, requests fall back to the old manual workflow. Many legacy systems don't support API-driven provisioning, which limits where you can actually implement it. In fast-changing environments like multi-cloud or Kubernetes-heavy architectures where new services spin up constantly, ensuring there's an IAM policy linked to every new object takes real discipline. And misconfiguration risk is the biggest concern - if someone writes a policy that gives everyone admin access, you need controls in place to catch that before it does damage.
Policy-based access control - real-time, per-request authorization
My perspective, and the reason I've spent the last five years building Cerbos, is that JIT is still a form of standing privilege. Yes, you've reduced the window. Maybe it's minutes instead of months. But you've still granted an identity a set of permissions for a duration. In the PBAC world, we're making access decisions on individual requests - every API call, every message into a queue, every endpoint hit.
I used a real example from Utility Warehouse in the UK, a Fortune 500 telecom group with 4,500 microservices in their architecture. Building and maintaining fine-grained roles across that many services in any manageable way through classical approaches just isn't possible. Policy-based access control changes the equation.
Here's how PBAC works in practice
Start with a business rule - say, a cardiologist should be able to access patient health records on a hospital-managed device, during business hours, with a recent MFA event. Today, that rule probably lives in someone's head, in a spreadsheet, or in scattered conditional logic across your codebase. With PBAC, you codify that business rule into a structured, human-readable policy file that captures all those conditions - role checks, device posture, time-of-day constraints, step-up authentication recency.
That policy then becomes a versionable, testable, auditable artefact. It lives in a Git repo. It goes through CI/CD pipelines. Every change is tracked, tested in isolation, and linked to a specific commit. When an auditor asks why a particular identity had access to a particular resource, you can trace it back to the exact version of the exact policy that made that decision, and the business justification that drove the change.
At runtime, every action passes through this policy engine - the policy decision point evaluates the request against current conditions and returns a binary allow or deny. The identity, the resource, the action, and all the contextual attributes get evaluated in the moment. No stored permissions to go stale. No privilege to creep.
This is what makes PBAC align so naturally with zero trust principles. Zero standing privilege. Dynamic, contextual, real-time. And because your policies are defined as code, you get the scalability and auditability that comes with treating authorization as a proper engineering discipline rather than an admin task.
The enforcement model is also inherently flexible. Because the interface is straightforward - pass in an identity, a resource, and an action, get back allow or deny - you can plug it into application services, API gateways, service meshes, VPN connections, legacy application proxies, and even in front of existing JIT systems. Each team can own their domain policies while a central governance function maintains visibility across the whole stack.
Where all that context comes from
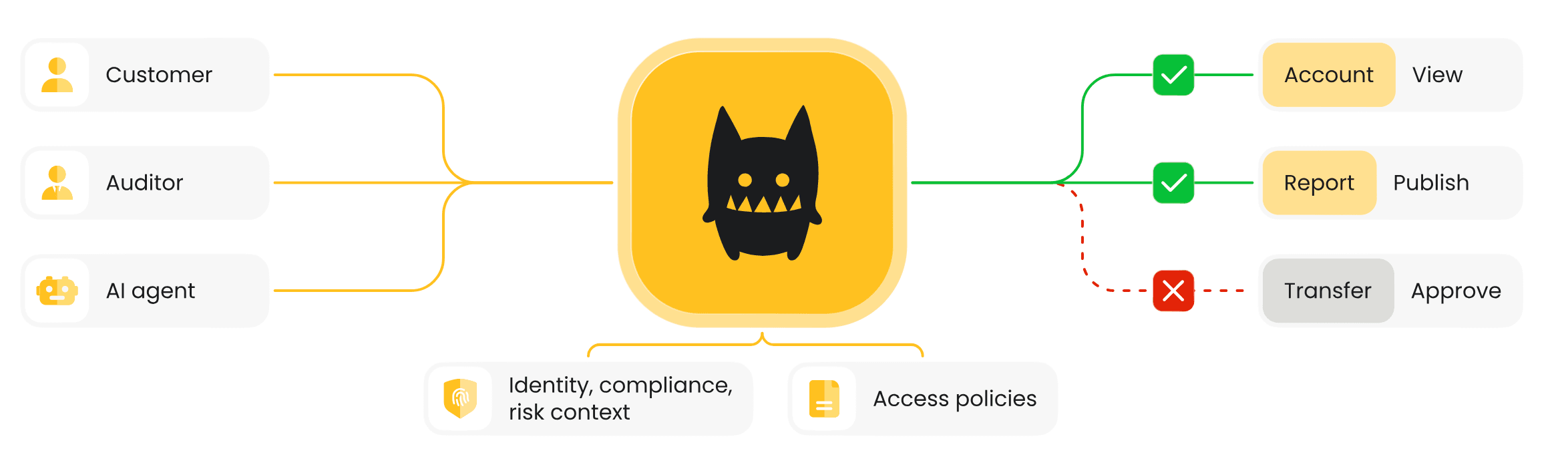
One thing I wanted to emphasize during the session is that PBAC doesn't work in isolation. The policy engine is the brain of the authorization logic, but it's fuelled by data from across the enterprise.
Whether someone holds the cardiologist role comes from your IDP or directory. The object they're interacting with comes from the application itself. Whether they're on a managed device comes from your device posture management system. Business hours might come from an HR system or on-call roster. Risk scores might come from a risk engine you may or may not have deployed yet.
For CISOs evaluating this, the key question isn't just "can we write policies" - it's "do we have the integrations in place to feed the right context into those policies?" If you have your IAM and IDP systems sorted, your applications provide resource context, and you have device posture and HR data flowing, you're in good shape to adopt this model. If some of those signals are missing, that's your integration roadmap.
Implementation - pick your path, start small, prove it
Vatsal laid out a practical framework for actually getting started, regardless of which approach resonates most. The key insight is that JIT and PBAC aren't competing. They're complementary, and the right path depends on where you are and what problems you need to solve first.
Path A is JIT-focused. If you already have an IGA solution deployed and your immediate concern is standing privileged access, start here. Layer JIT on top of your existing identity infrastructure to eliminate always-on admin accounts. This is a quick win that dramatically reduces your attack surface.
Path B is PBAC-focused. If your primary pain is authorization logic scattered across applications or the need for fine-grained, contextual access decisions, start by externalizing authorization from your applications into a centralized policy engine. This decouples access logic from application code and gives you consistent enforcement across services.
Path C is the combined strategy, and it's the one we all agreed is the ideal end state. Use PBAC for fine-grained runtime authorization across your application stack, and JIT for privileged access scenarios and legacy systems that can't support real-time policy evaluation.
Regardless of the path, the implementation follows a four-step process. First, assess and prioritize - map your processes, identify your most sensitive applications, and figure out where the biggest operational burden and security gaps are. Second, pilot a quick win - implement JIT for one admin tool or PBAC for one application, show leadership the results, and get buy-in to scale. Third, expand - start with simpler applications and work toward the complex legacy systems. Fourth, layer in AI to assist with risk-based decisions, dynamic scoring, and eventually policy generation from natural language.
Where AI fits (and where it absolutely does not)

The AI section of the panel was one I felt strongly about, and I'll repeat the hill I said I'd die - you should never, ever allow an LLM or AI system to make the actual access decision.
That decision must be deterministic. You cannot have a system hallucinating access because someone said the right magic words in a chatbot and suddenly they can see the entire HR database. No. The system that evaluates "can this identity do this action on this resource" must be based on defined policy, evaluated against real context, every single time.
Where AI genuinely helps is in everything around the decision. Behavioral recommendations from audit trail data - these users are requesting access they never use, these roles are overprovisioned, this attribute is carrying too much authorization weight. Anomaly detection on usage patterns to find overused, underused, or orphaned entitlements. Automated recertification based on actual usage rather than annual rubber-stamping exercises. Policy suggestions by analysing real-world behaviour and identifying where your model has drifted from reality.
The principle is simple - AI augments the decision-making process, it does not replace it. Use it for understanding, insight, and suggestions. Keep a human in the governance loop for the final deploy, the final definition, the final approval of what your policies should be.
Nandini also pointed to Google's white paper on building secure AI agents, which lays out the architecture for embedding access and identity-based principles into the agent lifecycle itself. It's a strong read and I'd recommend it to anyone thinking about how authorization intersects with agentic AI. PBAC is a foundational building block here - if you're going to tell an agent it cannot process a transaction on an application, you first have to externalize that authorization logic so a policy engine can evaluate it independently of the agent's reasoning.
The agent identity problem is real
We touched on agentic AI during the Q&A and it's worth flagging here. The challenge right now isn't just about authorizing agents - it's that we haven't solved agent identity.
What I'm seeing in the wild falls into two dangerous patterns. Either agents get a super-user service account that can do everything (because they're agents, they need broad access, right?), or they directly impersonate the user, which destroys auditability because the audit trail just looks like the user doing everything.
Neither works. What we actually need is a delegation model where an agent receives a scoped-down version of the user's permissions - a constrained token that says "User X has authorized Agent Y to perform these specific actions for this duration." There's active work happening in the OpenID Foundation (where we're working on the AuthZEN specification) and the IETF around transaction tokens and permission attenuation for agents. Standards like SPIFFE for cryptographically provable workload identity are part of this picture too - giving agents the same rigorous identity treatment as any other workload in your infrastructure.
Once we solve the identity layer, those agent identities simply become another input into your JIT or PBAC system. But we need to get the identity right first.
If you’re looking to safely expose tools to agents without compromising control, reliability, or auditability - read our technical guide, try out Cerbos, or read our ebook "Zero Trust for AI: Securing MCP Servers".
Key takeaways
If you take one thing from this post, let it be this - there is no single right answer. Don't let anyone tell you to go all-in on JIT or all-in on PBAC or RBAC or ABAC or any other acronym. Think about the problems you have in your organization, the questions you're trying to answer, the types of identities you need to govern, whether those are human, machine, or increasingly AI agents.
JIT and PBAC are both effective approaches, and they work best together. Pilot quick wins using whichever approach addresses your highest-priority risk, prove the value, and scale from there.
Build your IAM roadmap around your specific use cases, your asset inventory, and your access management principles. Define what maturity looks like for your organization, not someone else's.
And finally, embrace AI as an accelerator for understanding and improving your authorization posture, but keep deterministic policy enforcement at the core. The access decision itself must remain something you can explain, reproduce, audit, and defend.
Because when the board asks "who had access to what, and why?" - you need evidence, not guesswork.
FAQ
Tagged in





