At KubeCon North America 2025, AI agents dominated the conversation. Over 10,000 attendees packed the event, and every other conversation was about AI-driven automation and “agentic” systems. In a live Identerati Office Hours session, Alex Olivier, CPO and co-founder of Cerbos, discussed how the rise of AI agents, and the Model Context Protocol standard that connects them to tools, is converging with the industry’s push toward Zero Trust security.
This blog post distills that conversation. We’ll explore why AI agents need identities, just like human users or microservices do, how MCP works and what challenges it introduces, and how Zero Trust principles like fine-grained authentication and authorization for every request, can be applied to these agents. Along the way, we’ll examine current gaps, from the overuse of API keys to the lack of delegation standards, and highlight emerging best practices such as on-behalf-of tokens, embedded policy decision points, and OAuth 2.0 token exchange. By the end, you should have a clear understanding of how to make AI agents a trustworthy part of your architecture, without requiring viewers to have seen the original webinar. Let’s dive in.
AI agents meet Zero Trust. A new security frontier
AI agents - applications powered by large language models that can perform actions, are moving from demos and lab experiments into real production use cases. They might schedule meetings, pull data from internal systems, or even orchestrate infrastructure.
At the same time, organizations are embracing Zero Trust security models, which require authenticating and authorizing every workload and request rather than relying on perimeter defenses. As Alex Olivier noted, these two trends are on a collision course: “we have everything going on in the AI space - MCP, agents, etc. - and on the infrastructure side this move to actual Zero Trust… one of the core foundations of that is we need to start issuing actual identities to workloads”.
In essence, if an AI agent is going to access your services or data, it needs to prove its identity and be treated as an independent entity in your security architecture. Gone are the days of blindly trusting anything running inside your network. Instead, every agent or automated process should be authenticated (who/what is it?) and authorized (what is it allowed to do?) just like a human user or a microservice in a zero-trust environment.
Why AI agents need identities, and more than a hardcoded API key
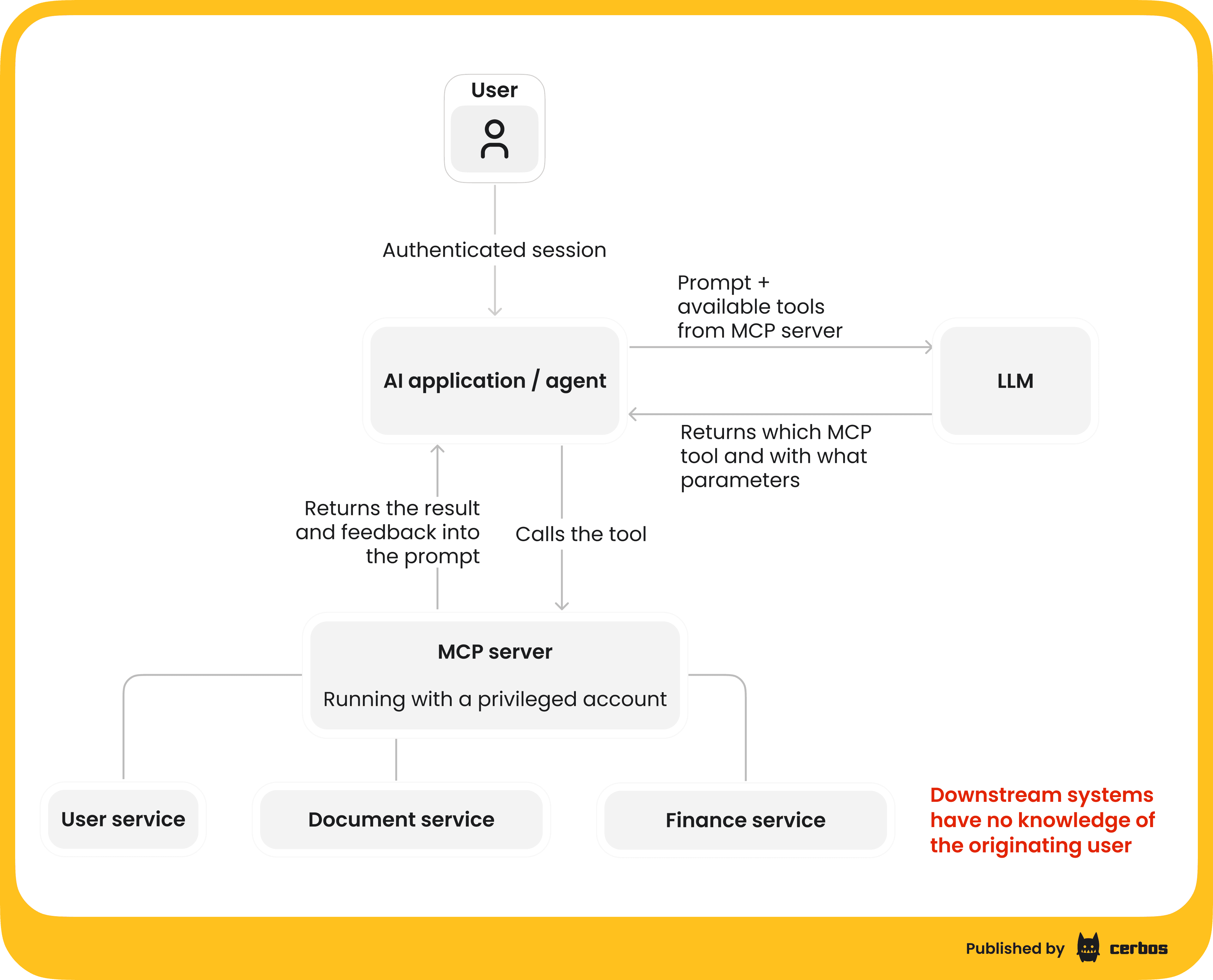
When a new AI agent “spins up” to handle a task, for example, an AI assistant launched to manage your calendar, how do your systems know if it should be allowed to do something? In early experiments, many developers took shortcuts: the agent simply used a copy of the user’s API key or an admin token to access systems. Looking at the current MCP ecosystem, most implementations still rely on static API keys rather than modern OAuth-based authorization models. An API key is basically a magic string, like a username with no password, that grants broad access. This is far from least privilege or Zero Trust; it’s more like a skeleton key that could be abused if leaked.
Olivier expressed some frustration with this state of affairs. AI developers are excited to build new capabilities, but “they’re still just issuing an API key as a string… it’s like a username without a password, exactly”. He quipped that it would have been nicer if the AI platforms such as OpenAI, Anthropic’s Claude, Google Gemini, etc. at least started with a more secure mechanism, e.g. mutual TLS certs or proper OAuth flows, instead of defaulting to API keys. At minimum, if secrets are used, developers should follow best practices - store keys in a vault or environment variable, not commit them in code. But the real goal should be to move away from static keys entirely in favor of short-lived, scoped credentials tied to a real identity.
In a Zero Trust model, every agent needs a unique identity issued by a trusted authority. That identity could be established via mechanisms like SPIFFE/SPIRE for workloads in your infrastructure, or OAuth2 client credentials for external services. The identity lets you attach attributes or claims to the agent. For example, “This is the SalesBot agent running for user Alice.” With that, you can audit what the agent does and apply policies to constrain it. This is much better than sharing one generic “service account” or API key among many agents. As Olivier put it, the “bad model is giving [agents] a service account that has broad access to basically anything”. Instead, we want to scope down what each agent can do to the minimum it needs for its task.
Introducing Model Context Protocol - and its challenges
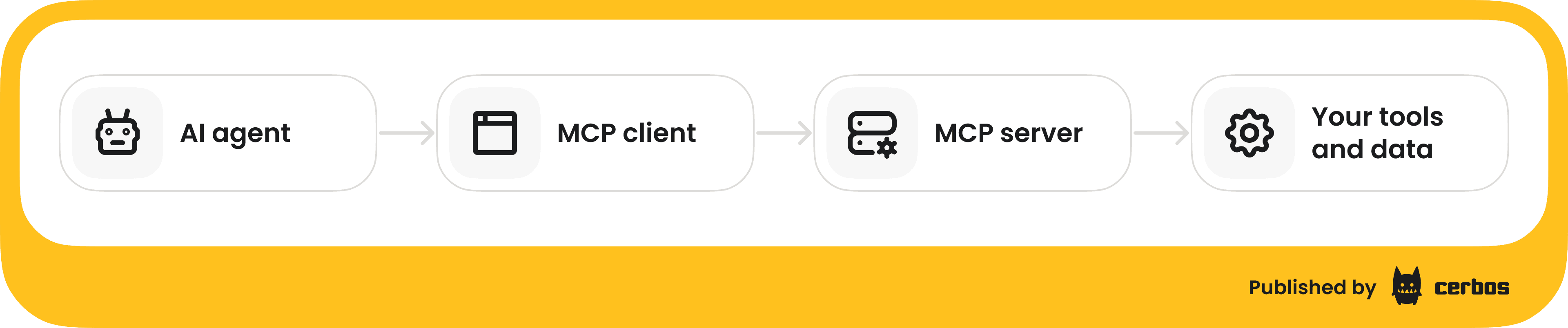
Many AI agents use MCP to interface with external tools and data. MCP is an open standard, spearheaded by Anthropic and others, that defines how an AI application (the MCP client/host, e.g. an LLM or an agent hub) can connect to one or more MCP servers which expose functionality. In simpler terms, an MCP server is like a “tool API” that an AI agent can call.
For example, an MCP server might provide a lookup_customer_by_email tool, a database resource the model can query, or a template prompt it can use. Through MCP, an agent can extend beyond its built-in knowledge and take actions in the real world via those tools.
How MCP works
The agent’s runtime, say, your AI assistant application or an IDE like VS Code, will act as an MCP client and connect to one or more MCP servers. These connections can be local, via STDIO pipes for a local process, or remote, via HTTP or Server-Sent Events. Each server advertises its capabilities - the tools, data, or prompts it offers. The agent’s LLM is then able to call those tools by sending JSON requests to the MCP server, which executes the action and returns results.
MCP-related challenges
MCP is powerful because it standardizes how tools are described and invoked. However, it also introduces new security and scalability challenges.
Context window bloat
Every MCP server the agent connects adds a description of its tools into the LLM’s prompt context. Each tool might have a description of what it does, allowed arguments, etc. If you connect an agent to many tools; for example, your GitHub, your calendar, Slack, database, etc., you could “pollute” the prompt with a huge list of tool descriptions.
Olivier noted that if you have enough MCP servers, “by the time you have maybe a few of these - your Linear, your GitHub, your Figma, whatever - you start chipping away at how much token space you have for the actual task” because the prompt is filled with tool definitions. This is inefficient and can hit LLM context length limits. Researchers are already exploring solutions like selective tool disclosure (only telling the model about relevant tools for a given query) and using retrieval techniques to pull in tool info on the fly rather than up-front.
Uncontrolled tool visibility
By default, an MCP client can discover all available tools on a connected server. But should an agent or user see every tool? In an enterprise, some tools are sensitive. For example, you might have an MCP server exposing HR data queries and another for public knowledge base searches. Not every agent or user prompt should surface the HR tools. The MCP spec mentions authentication/authorization in passing, but it doesn’t define how to enforce it.
Olivier described the need for policy checks here: an MCP server should ideally filter which tools or resources it exposes to a given agent or user. Who can see or call a particular tool may depend on identity and context. For instance, a sales department agent might be allowed to use the lookup_customer tool, but an external-facing support bot should not.
We at Cerbos have worked on integrating policy enforcement into MCP frameworks (like FastMCP), so that teams can impose both coarse-grained and fine-grained authorization; controlling not only which tools are available, but also with what parameters they can be invoked.
Lack of standards for discovery & metadata
MCP does include a discovery mechanism - the client can ask the server what tools/resources it offers. However, enterprise needs may go further. For example, indicating which user roles can access a tool, or tagging tools with sensitivity levels. There’s early discussion in the community about an “enterprise profile” for MCP that would let servers publish such metadata. This would help organizations catalog what agents could do, and apply governance, like only exposing certain tools to agents that have a certain trust level or user’s consent. For now, much of this is ad-hoc - a gap waiting to be filled as MCP adoption grows.
In short, MCP gives us the connective tissue to plug AI agents into real-world actions, but we must be careful to secure those connections. Let’s consider two scenarios: internal agents vs. external agents.
Internal agents vs. shadow IT 2.0
Inside a company, different teams might spin up their own AI agents or MCP servers - e.g., a DevOps agent that can restart servers, a sales agent that can update CRM records, etc. With proper planning, these can be integrated into a shared framework where IT knows what’s running. Policies can be put in place to ensure each agent only does what it’s supposed to. Olivier notes many organizations are now moving from “lab experiments” to productionizing agents for real business use cases, which means “making sure we have the same level of security controls around it” as any production system. That includes issuing them identities, auditing their actions, and managing their permissions over time.
More on how to safely expose tools to agents without compromising control, reliability, or auditability, using fine-grained permissions in this guide.
The trickier scenario is what Mike Schwartz dubbed “Shadow IT 2.0.” This is when well-meaning employees sign up for external AI services and connect them to company data without IT’s oversight. For example, an employee might try a new AI assistant app that asks to connect to the company’s GitHub, Jira, or Google Drive. In doing so, they could inadvertently grant a third-party agent broad access to corporate data - bypassing normal access controls and audits. As Olivier explained, “you end up with uncontrolled data access going on… not through your corporate security structure”. This isn’t a brand-new problem; people have been plugging cloud apps into work accounts for years. But AI agents amplify it because they can automate complex sequences of actions once let in.
What can be done? One approach is to enforce use of an Agent Gateway - essentially a proxy that all AI agent traffic, especially to external MCP servers, must go through. In fact, the CNCF has a project underway for an “Agent Gateway” to serve as that policy enforcement point. Similar to an API gateway, an Agent Gateway could authenticate agents, terminate their connections, check requests against policy, and forward them to allowed services. Many vendors are pivoting their existing gateway products to handle MCP or agent APIs. Schwartz joked “you throw a rock and hit 10 gateways” now supporting MCP. The gateway can be a central choke point to apply enterprise security controls - for example, blocking an agent’s attempt to access a sensitive HR system if it’s not approved, or ensuring all agent requests include a valid identity token.
However, a gateway is not a silver bullet. In true Zero Trust spirit, we ideally should not implicitly trust the gateway either. It’s a helpful enforcement layer, especially for legacy or third-party integration, but security architects should assume an agent might find a path around it. The ultimate goal is deeper: push identity and policy down to the level of each service and each agent, such that even if an agent got network access to a backend, it still couldn’t do harm without the right token and permissions.

AI agents expose your weakest links
If there’s one takeaway for security teams, it’s that AI agents will quickly find any gaps in your Zero Trust implementation. Unlike a cautious human employee, a scripted agent will relentlessly try whatever actions it’s been directed to do, without a “moral compass” or gut feeling to stop it. If an internal permission model is overly broad, the agent might inadvertently exploit that. For example, if a monitoring agent is given credentials that technically allow it to read customer data, because no one bothered to restrict them, it will cheerfully go ahead and fetch it. As Olivier put it, “these models are just gonna try everything all at once… without any kind of moral compass. And if it can do something a human probably wouldn’t, that’s only exposing a flaw in your security model. It’s highlighting what you already have in place - or don’t have - in terms of proper authentication, authorization, trust boundaries”.

In other words, many agent-related breaches will really be existing security oversights made visible. An agent retrieving data it shouldn’t have is no different from a malicious insider or hacked service doing so; the difference is that now even “benign” AI processes could stumble into those paths unless we lock them down. This puts pressure on teams to implement least privilege everywhere; not just for human users, but for service accounts, API keys, and agents.
Mike Schwartz enumerated a “whole landscape of security deficiencies” that we need to address for agents:
-
We have no standard way to discover what agents are out there, both within our org and external ones that want access.
-
We lack a standard way to register agents or clients. Some analog of dynamic client registration in OAuth, but with richer metadata for agent capabilities.
-
We lack consistent means to authenticate agents - issuing them credentials tied to their identity.
-
We lack mechanisms for agents to obtain user consent or delegation tokens on the user’s behalf in a standardized way.
-
We don’t have established policy frameworks for these delegation chains, e.g. allowing an agent to act on behalf of a user under certain conditions but not others.
It’s a long list, and the industry is just beginning to work on it. So what can we do today to start closing these gaps?
On-behalf-of: Delegation tokens for AI agents
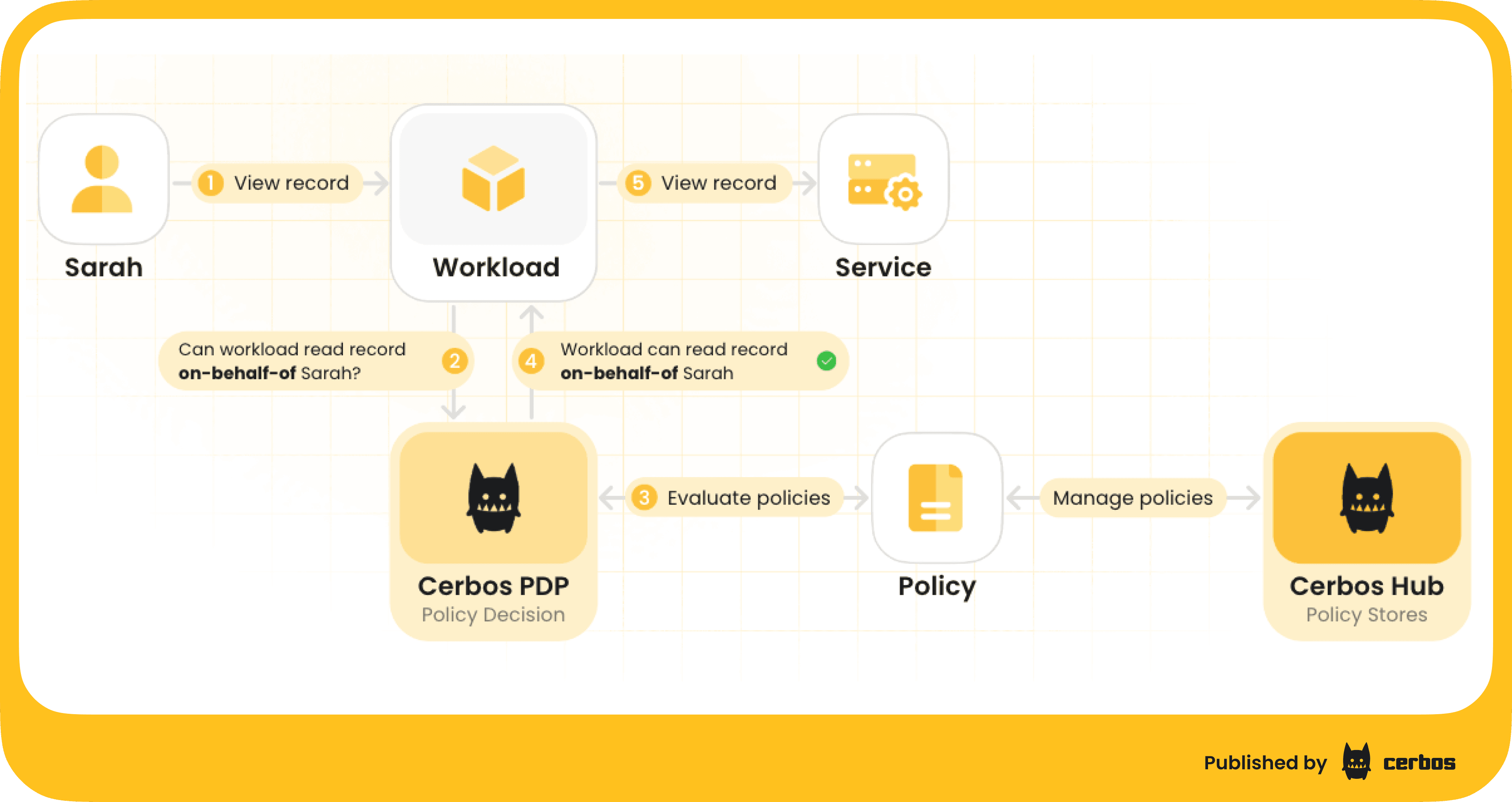
One immediate step is to leverage concepts we already use in identity systems, like OAuth 2.0 delegation. Rather than giving an agent unfettered access, we can issue it a token that clearly states “Agent X is acting on behalf of User Y”. In OAuth terms, this can be modeled by token exchange or the “on-behalf-of” flow (RFC 8693). Alex Olivier highlighted that a lot of us in the community are aiming to “get to the on-behalf-of point” as a first milestone.
Here’s how that might look: when a user initiates an AI agent to do something, the system would call an authorization server to mint a special access token for the agent. That token would include the agent’s own identity, as the actor or authorized party, and the user’s identity, as the subject or delegate. Plus a very limited scope of what it can do. For example, a token might say: subject = Sarah, actor = CalendarAI, scope = “read:recordX”. The agent then presents this token when calling the calendar API. The calendar service can see that the request is Sarah’s data accessed by the CalendarAI agent, and enforce that it only performs read operations. This provides accountability - every action can be traced to a user and agent, and fine-grained control - the agent can’t exceed the scope.
Importantly, these tokens should be short-lived and tightly scoped. If the agent dies or the user revokes access, the token expires and cannot be used further. This is a much safer model than, say, giving the agent your personal long-lived API key. It also means that if the agent is compromised or goes rogue, the damage is limited to what that one token allowed - it can’t, or shouldn’t, call unrelated services or perform higher-privilege tasks.
Several major providers are working on such delegation schemes. For instance, Auth0’s “Token Vault”, recently announced in 2025, uses OAuth token exchange under the hood to let AI agents request tokens for third-party APIs on behalf of a user. Instead of storing a Google refresh token for an agent, the agent trades an internal token for a Google API token when needed - and that returned token is specific to the task (e.g. “read calendar for next 10 minutes”). This approach keeps the most sensitive credentials like refresh tokens in a secure vault and only gives the agent just-in-time, just-enough access.
The concept of on-behalf-of delegation isn’t new - we’ve had OAuth flows for service-to-service delegation and user impersonation for years, but applying it to AI agents is new territory. Expect to see new standards and profiles emerging to handle multi-hop delegation (user → agent service → tool API) with proper token chaining. It’s complex, but the security payoff is huge: we get an audit trail of who did what via which agent, and we can write policies like “Agent X can only perform actions that User Y could perform themselves”. Olivier emphasized that at least getting this chain visible is key: “here’s an action being done by an agent on behalf of someone - at least at that point we can start making policy decisions”.
Don’t let AI agents “hide” behind users
One thing to avoid is the trap of agents fully masquerading as users in an undifferentiated way. For example, some current personal assistant tools simply control your browser or use your session cookies to act exactly as “you.” This makes it impossible for backend systems to tell if it was you or the AI bot taking an action, and therefore impossible to apply different rules or audit properly. Olivier warns against these “browser automation” or RPA-style agents that “take over your Chrome instance and act as you” without any checkpoints. From a security standpoint, that’s a nightmare - it erases the identity boundary between the human and the code. If the agent does something unintended or malicious, it will look like the human did it.
So, as you design AI agent integrations, maintain a clear separation: the agent is not the user, even if it operates on the user’s behalf. The agent should have its own credentials and context. For instance, an agent might use the user’s OAuth token to get a limited downstream token, as described above, but that downstream token can still carry an indicator that “this is via Agent X.” That way, the target service could log “Agent X (for Alice) accessed this data” rather than just “Alice did X.” This distinction is crucial for both security and compliance.
Giving AI agents a coral compass: Embedded policy checks
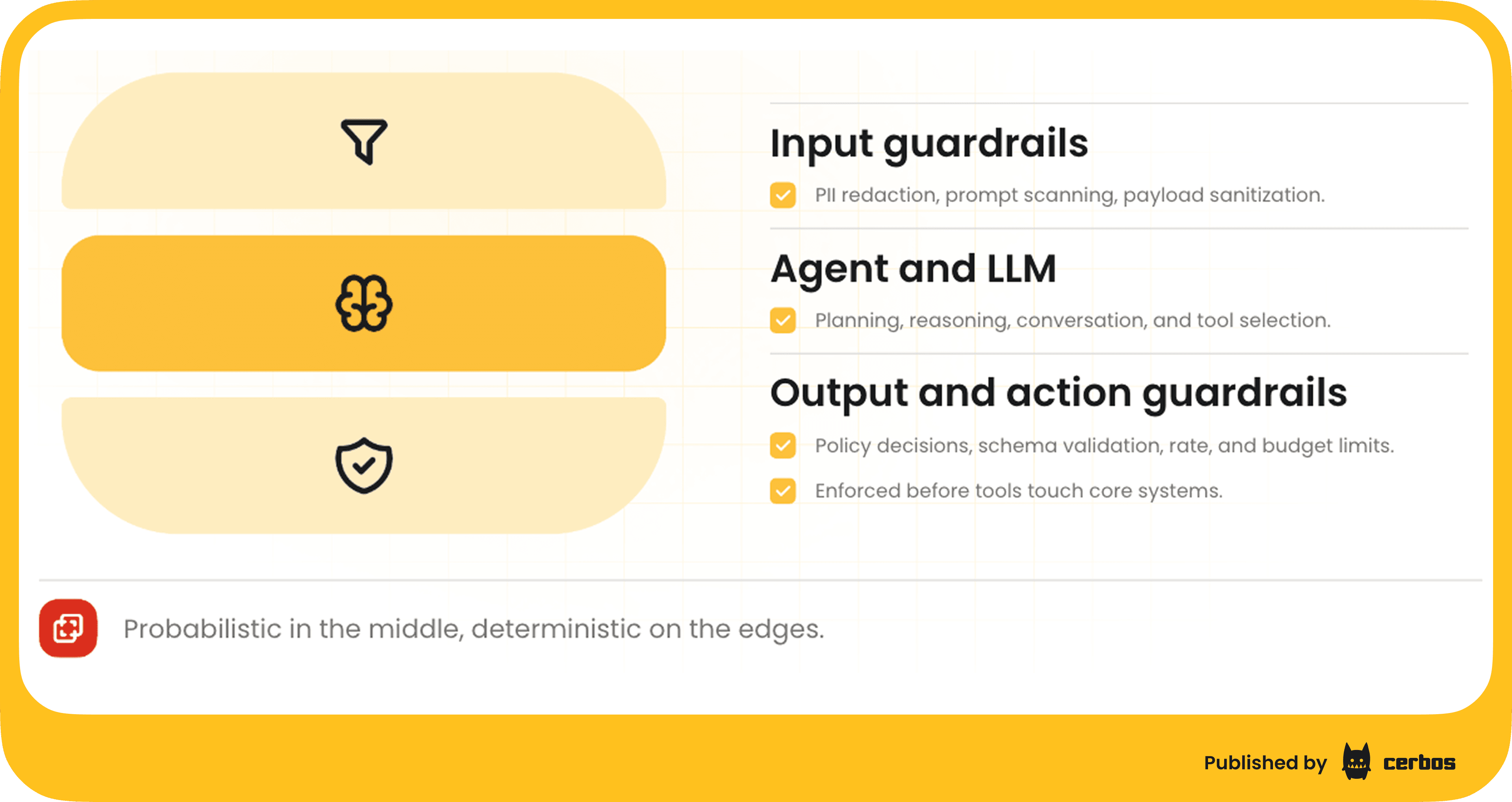
So far, we’ve discussed controlling agents from the outside; via identity, tokens, gateways, and service-side policy. Another intriguing idea is controlling agents from the inside. In other words, could we embed a sort of governor or Policy Decision Point within the agent’s own code that intercepts its actions?
Mike Schwartz illustrated this with a sci-fi analogy from the “Murderbot” stories: the robot has a built-in governor module that prevents it from doing unauthorized things, like harming humans. While our software agents aren’t wielding weapons, the principle stands: we might want an agent’s runtime to self-check each potentially risky action against a rule set: “Am I allowed to do this?”. This could prevent an agent from, say, deleting all records or emailing data externally, even if it “thought” that was a good idea. Essentially, the agent would carry a miniature authorization engine with it.
Olivier found this concept apt, noting that we’ve been discussing how to embed authorization logic wherever needed. Cerbos provides an externalized authorization engine that can run as a service or library, and he sees a future where this can run inside agents too. “Being able to push the PDP to as many layers of the architecture as possible is the direction things have to go… down to an agent, down to a workload, down to physical hardware”. This aligns with the idea of “shift down” in security: instead of only having centralized policy at the API gateway or application level, make it ubiquitous - every component, even an AI agent process, consults the policy before executing critical actions.
Of course, an agent could ignore its internal PDP if it’s compromised, just like malware can ignore OS security features, but if the agent platform is designed to be policy-aware from the start, it adds another layer of defense. For example, an enterprise could mandate that all internal AI agents include a policy SDK that checks corporate rules, perhaps fetched from a central server or baked into the agent container. This might specify that “finance data can only be accessed during business hours and never sent to external email”, etc. The agent would then refuse to perform disallowed actions, even if prompted or instructed by the LLM output.
Olivier also made an important point: keep the actual decision-making deterministic. AI can assist in writing policies or analyzing logs, but when it comes to the moment of “allow or deny,” you don’t want an LLM’s probabilistic guess. “You do not want [an AI] hallucinating an ‘allow’ when there should be a denial, or vice versa,” he said. In practice, that means the PDP, whether external or embedded, should use traditional rule engines or code - something testable and reliable - rather than delegating the final call to an AI. We might use AI to recommend policy changes or find anomalies, but the enforcement needs to be rock-solid and explainable.
If you’re looking to safely expose tools to agents without compromising control, reliability, or auditability - try out Cerbos Hub, read our ebook "Zero Trust for AI: Securing MCP Servers", or speak to an engineer for further details.
“Shift down” toward distributed, deterministic authorization
This vision of embedded authorization feeds into the broader Zero Trust architecture. Zero Trust tells us to “never trust, always verify” - and that applies not just at your network perimeter, but everywhere in your stack.

As Olivier remarked, “we finally have the tech components and workflows where we can actually have zero trust - where your trust domain is essentially down to a single request, to a single service”. Achieving that means each service or agent evaluates credentials and policy on each request, with no implicit trust just because a call originates from inside the network or from a “trusted” process.
Key enablers of this distributed approach include: Kubernetes, which makes it easier to inject sidecar proxies or libraries into services, service mesh frameworks, and WebAssembly modules that can run policy engines in-process. For example, Cerbos can compile policies to WASM and embed the PDP right into an app or agent process, eliminating network calls to check permissions. This means even if the agent is running on a developer’s laptop or a server outside your control, the same consistent policy logic can accompany it.
Another enabler is the modern identity ecosystem: projects like SPIFFE provide a way to issue cryptographic identities to ephemeral workloads, including containers or even serverless functions. Cloud providers have their own flavor of this (e.g. AWS’s instance roles, GCP’s service accounts) which can be federated. With a solid identity for each agent and service, we can implement mutual authentication everywhere; every call presents a proof of who it is. Combine that with policy, and you get mutual authorization as well - each side can check if the other is allowed to talk to it.
This is the opposite of the old model where, say, all microservices behind a firewall might trust each other by default. In a zero trust world, Service A receiving a request from Service B should authenticate B’s identity and then consult policy: “Is B allowed to call me asking for this data, on behalf of user U?” - every time. It may sound expensive, but with efficient token passing and local PDP evaluation, it can be done with minimal latency - some advanced PDPs like Cerbos PDP respond in sub-milliseconds. Plus, token exchange (discussed below) can ensure tokens stay short-lived and specific to each request, reducing replay risks.
Bridging to legacy systems
While it’s exciting to design new greenfield systems with these principles, most of us have legacy applications that were never built for zero trust or fine-grained auth. You might wonder: How do we bring Zero Trust to an app that doesn’t even know what an “identity token” is? For those cases, a pragmatic approach is often to put a proxy in front of the legacy app. This could be an OAuth2/OIDC proxy or API gateway that terminates incoming tokens, performs the authZ check, then passes the request to the old app, which now only accepts traffic from the proxy. For example, IBM and Red Hat demonstrated a solution using Keycloak, an open source IdP, with an Envoy proxy to enforce zero trust principles in front of a legacy service.
This pattern, let’s call it “Zero-Trust Sandwich”, does improve the situation: the legacy app now only sees requests that have been vetted, and we get an external policy control point.
However, it’s not “pure” zero trust because the app itself remains unaware and could be tricked if someone bypasses the proxy. As Schwartz joked, calling that zero trust is a bit ironic, “isn’t the definition of zero trust that the proxy is one component that can’t be trusted?”. Still, in many environments, this is the practical way forward until you can replace or refactor the legacy system. It gives you something like 0.1 trust (not zero, but better than before), which might be acceptable for a transition period.
The key is to be honest about the trade-offs. If you deploy such proxies, monitor them closely - they become high-value targets. And whenever possible, plan to sunset legacy auth in favor of built-in, distributed auth. Over time, you can move the enforcement closer to the code; e.g. using libraries or sidecars in the same process space as the app, and reduce reliance on the external proxy.
Token exchange: Narrowing the scope, hop by hop
A critical mechanism in making zero trust practical is OAuth 2.0 Token Exchange (RFC 8693). This standard allows one service or component to exchange an incoming token for a new token to call the next service. Why do this? Because it lets you narrow the scope and audience of tokens at each hop. Instead of passing around one all-powerful user token through the entire call chain, which could be stolen and misused, each service along the path gets a token that’s just for it and for the specific downstream it needs to call.
For example, imagine a user interface calls Service A with a token. If A needs to call Service B, rather than forwarding the user’s token, which might allow things B shouldn’t do, A performs a token exchange: it sends the user token to the auth server, along with its own identity, asking “Please give me a token to call B, on behalf of this user, with only the permissions needed for what I’m doing.” The auth server returns a new token, intended for Service B. A then calls B with that token. B can verify the token was issued to A for B, and possibly that it’s constrained to certain scopes or a subset of user claims.
This achieves a few things:
| What is achieved | Explanation |
|---|---|
| Principle of least privilege | The token B sees might, for instance, allow read access to a particular record but nothing else. Even if B’s token is stolen, it can’t be used to call C or perform unrelated actions. |
| Context propagation | The exchanged token can carry context like “transaction ID” or “session”, so B knows the call chain context, not just the user. This is why the emerging “transaction token” profile of OAuth is interesting - it packages up the user, the service actor, and other context into one token meant for a single transaction. |
| Trust but verify the caller | B doesn’t have to blindly trust A’s word about who the user is; the token comes from a trusted authority (e.g. your IdP) and confirms that “A is calling on behalf of user U”. This prevents the confused deputy problem where a service might misuse another’s token. In essence, token exchange provides proof-of-possession and intent at each step. |
At KubeCon, speakers from IBM/RedHat showed a demo where every microservice call did a token exchange to get a new token. This may sound heavy, but modern IAM systems can handle high token issuance rates, and the tokens can be kept very lightweight - JWTs or even references. Yahoo reportedly implemented a large-scale token exchange system and found it scalable and beneficial. The audience may not have fully appreciated the nuance, but it’s a big deal for security: it means a compromised token on one service can’t simply be replayed elsewhere, and each service has cryptographic assurance about who it’s really dealing with.
Alex Olivier agreed that transaction-scoped tokens are “definitely the right direction” to bring the authorization context down to each individual operation. However, he noted adoption is still nascent - “we’re a long way from mass adoption of that concept”. Some challenges include the added complexity and latency of extra token calls, and the need for services to be designed to handle them. There’s also ongoing work to standardize what goes into a transaction token, beyond just user and audience - possibly nonces, timestamps, etc., to bind it tightly to the request.
Crucially, as Schwartz and Olivier both emphasized, having fancy scoped tokens doesn’t eliminate the need for policy. A token might say “User is an admin” or “allowed actions: X, Y”, but the service still must check if X or Y is actually permitted on the specific resource or in the current context. Authorization is not just reading a token - it’s making a decision with business logic. So think of these tokens as better inputs to your policy engine. They carry more information, and less ambient authority, than a typical session token. Your service or PDP can then evaluate, “Given this user, this agent acting on their behalf, and this context - do we allow this operation?”. The answer may involve looking at the token claims, consulting external data like resource ownership, and applying rules. All that still needs to happen at runtime, every time.
TL;DR: Building trustworthy AI agent ecosystems
AI agents are poised to boost productivity and automate countless tasks, but without the right security guardrails, they could just as easily become conduits for breaches or compliance nightmares.
The convergence of Model Context Protocol with Zero Trust is an opportunity to get things right from the start. We should treat agents as first-class identities, issue them credentials, limit their powers, and monitor their actions just like we do for human users and microservices.
To recap key recommendations:
-
Give each agent a unique identity - whether via SPIFFE, OAuth client credentials, or another mechanism. No more shared admin tokens or static API keys floating around.
-
Use delegation tokens and on-behalf-of flows for agents acting on user data. Ensure the agent never possesses long-lived user credentials; instead, let it request narrowly-scoped access tokens when needed.
-
Enforce least privilege on tools exposed via MCP. Not every agent needs every tool. Implement authorization in MCP servers to filter and scope tool use per agent/user/context.
-
Deploy policy enforcement close to the action. Consider agent-side policy checks or at least service-side PDPs that evaluate each request. External gateways are helpful, but strive for in-depth, distributed controls.
-
Embrace token exchange in your architecture. It adds initial complexity but pays off in limiting trust spans. Each service should prefer receiving a fresh, targeted token over a chain of forwarded ones.
-
Audit and log everything. With agents running around, having a unified audit trail (user X via agent Y did Z at time T) is crucial for trust. Many externalized authorization systems such as Cerbos can produce centralized decision logs which are invaluable for forensics and accountability.
-
Educate users and developers. Shadow IT won’t go away by policy alone - people need to understand the risks of hooking up unvetted AI services. Likewise, developers should learn to use secure patterns such as OAuth and identity federation, rather than quick-and-dirty API keys.
The story from KubeCon was one of both excitement and caution. The technology to do this right - identity protocols, policy engines, distributed tracing of identity - largely exists or is maturing. But we must apply it diligently to the AI agent world. As Alex Olivier said, much of what needs doing isn’t reinventing the wheel; it’s “solving problems we actually solved 5, 10, 15 years ago in IAM, but applying them to this new context”. By reusing battle-tested ideas, like OAuth, stateless tokens, RBAC/ABAC policies, and extending them where needed (standards for agent metadata, enterprise MCP profiles, etc.), we can avoid creating an insecure “Wild West” of agents.
Moving forward, expect rapid evolution in this space. Standards bodies and open source communities are already collaborating on frameworks for identity-aware agents. Gartner and other industry groups are holding interoperability demos - as hinted in the conversation, one of those is the AuthZEN interop which involves IDP and PDP integrations. It’s an exciting time, but also a critical one to ensure security keeps pace with innovation. The goal is that a year or two from now, we’ll be talking about how AI agents increased productivity without compromising security, thanks to thoughtful architecture.
In summary, MCP and Zero Trust don’t just make a clever rhyme. Together, they form the blueprint of a secure, modern infrastructure where AI agents can be empowered to do great things, but within clear guardrails of identity, context, and policy. It’s up to us as technology leaders to implement those guardrails now, so we can reap the benefits of AI safely and responsibly.
If you’re looking to safely expose tools to agents without compromising control, reliability, or auditability - read our technical guide, try out Cerbos, or read our ebook "Zero Trust for AI: Securing MCP Servers".
FAQ
Tagged in





